
The first problem you face when starting with machine learning:
Finding the perfect balance between training for too long or not training enough.
Either one and your model will be trash.
Here is the simplest and one of the most effective ways to work around this:
First of all, remember this:
• Overfitting will likely happen if you train for too long.
• Underfitting will likely happen if you don't train long enough.
It's not about time, but about number of iterations—or epochs.
We need a way to find the correct number.
First idea:
Use a separate holdout set to evaluate how the model is doing while we train it.
We can evaluate it after each iteration and stop the process as soon as the model's performance degrades.
We want to stop at the sweet spot in the attached chart.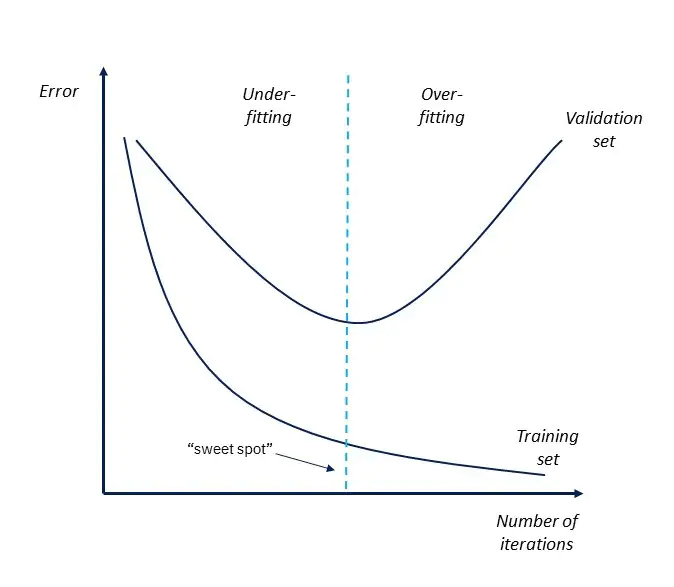
Notice that the chart shows the "error" of the model.
We call this "loss."
We want the holdout validation set and a metric (in this case, the validation loss.) We can also use any metric to determine when overfitting starts happening.
But there's a problem:
I don't want to draw a chart and find the sweet spot every time I need to do this.
I don't want to do any manual work.
How can we stop the model automatically when it starts overfitting?
Let's think about it:
The loss might be noisy: it will oscillate up and down.
We can't stop the process the first time the loss increases because it might be too early.
We need to wait for a few consecutive values going in the wrong direction before stopping the process.
One last problem: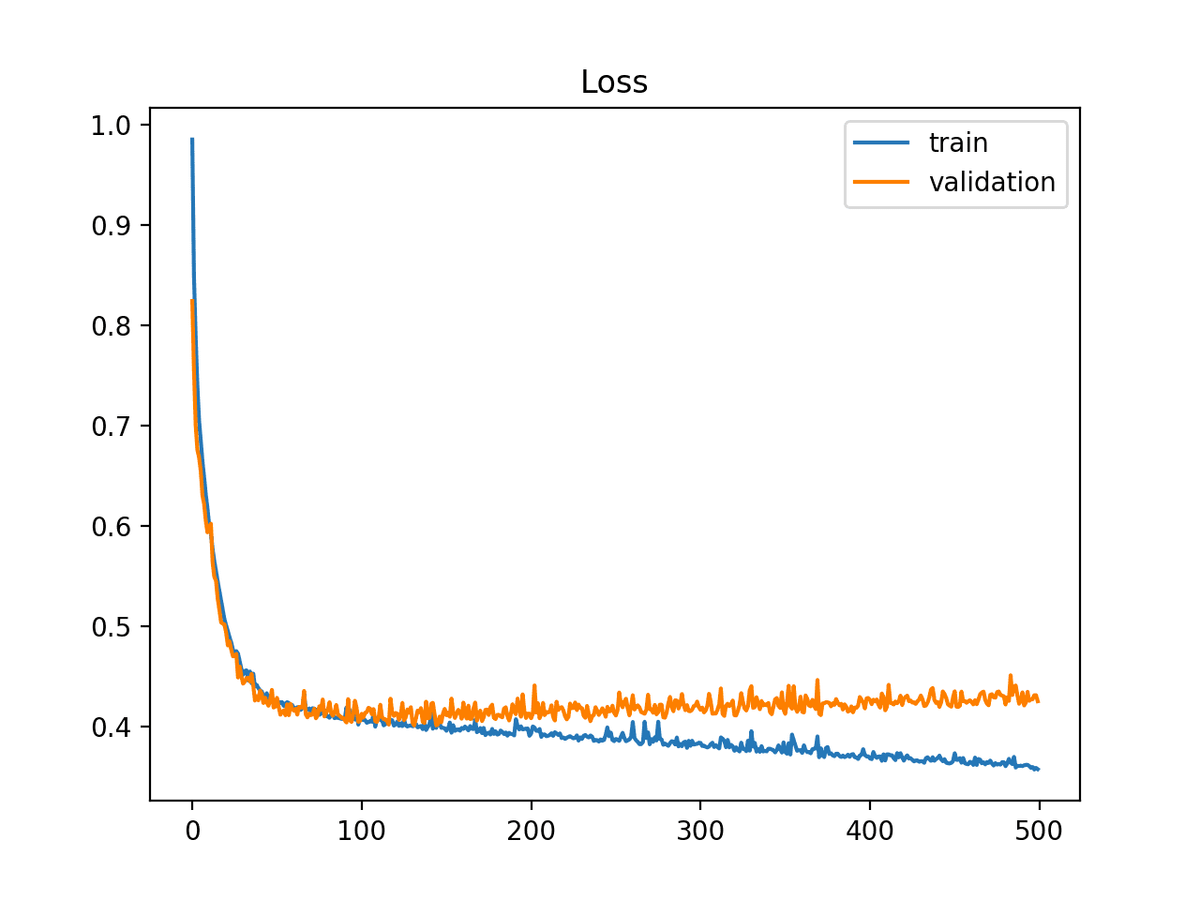
Let's say we wait for the loss to increase for 5 consecutive epochs before we stop training.
At that point, our model has been overfitting for 5 epochs. We don't want that!
We want the model we had 5 epochs ago.
How do we do this?
As we train the model, we can save the model as long as its validation loss is better than the last copy we saved.
• Run one iteration
• If the loss is better, save a copy
If we do this, we will have the best model saved and ready to use when we stop the process.
This process is called Early Stopping and every major library supports it.
The three ingredients we need to make it happen:
• A holdout set
• A metric
• A trigger with patience
• A way to save the best model
Twitter is great, but nothing beats YouTube if you want to understand a topic.
I recorded a YouTube video that goes into more details:
youtu.be/CODw8292uqE
Every week, I break down machine learning concepts to give you ideas on applying them in real-life situations.
Follow me @svpino to ensure you don't miss what's coming next.