1/57 🧵 Long overdue thread on AI — PART 1
We'll cover:
- What is artificial intelligence?
- What is machine learning? (+ example: spam filtering)
- The basics of neural networks
- How StableDiffusion & DALL-E work (high-level)
Unrolled: typefully.com/norswap/SUF6F2F
2/ I had to split this thread because it became too big :')
Next time I want to cover:
- How ChatGPT works (+ many good links)
- The fundamental limitations of neural networks
- AGI (general AI) & super AI: how close are we / what is missing
- How dangerous is super AI?
3/ Why this thread: too many bad takes on AI's relevance in the future. I wanted to write something I could point people to in future discussions on the topic :)
DISCLAIMER: This will probably contain some mistakes / simplifications / inaccuracies. Feel free to point them out!
4/ What even is artificial intelligence?
It covers a lot of things. In the 80s, a Makefile was considered AI (it's a rule-base "expert system"), so were logical programming languages like Prolog.
5/ A classical AI curriculum will walk you through fairly straightforward optimization techniques, including tree search + pruning and ordering heuristics (e.g. MinMax).
6/ Other technique includes:
- Linear Programming (LP
- Integer (Linear) Programming (I(L)P)
These help you find an optimal solution to a problem that can be defined as a set of linear (in)equalities.
7/ (The integer version restricts the variables to be integers.)
- Gradient descent — a way to find the minimum (or maximum) in a multi-variate function.
8/
- Lagrange multipliers — a way to convert a constrained problem into a function, such that it can be solved via gradient descent.
9/ The gradient descent is particularly fundamental, and is an important component of the algorithm ("backpropagation") that helps train neural networks (more of this in a minute).
10/ Some links to familiarize yourself with gradient descent:
- betterexplained.com/articles/vector-calculus-understanding-the-gradient/
- builtin.com/data-science/gradient-descent
11/ All of these techniques are well-suited for solving complete information games (e.g. chess) and optimization problems.
For example, check the Google HashCode competition problems, e.g. codingcompetitions.withgoogle.com/hashcode/round/00000000008f5ca9/00000000008f6f33)
12/ These optimization problems are also very common in the field of logistics: establishing schedules under a set of constraints / or preferences (e.g. to schedule exams or classes), vehicle routing, filling delivery trucks with packages Tetris-style, ...
13/ But people kind of take all of this for granted. While these problems are really difficult, machines have been better at them than us for a long time.
14/ In fact, machines' greatest asset is their ability to crunch a bunch of data/paths really fast. The "intelligence" we inject into these algorithms are heuristics and guide rails to get to a solution even faster.
15/ The reason why this is not so impressive to us is that it's based on *formal* reasoning. Rules are expressed in an unambiguous language that computers can understand and process.
They just run a guided search program that we wrote — and can reason about to some extent.
16/ The recent AI hype is all about machine learning, and in particular neural networks. Neural networks feel magical for numerous reasons.
17/ (1) We are not explicitly coding the rules or the heuristics that the machine follows. Instead, these are *learned* from a corpus of examples.
18/ (2) We can't really reason about what exactly the neural network has "learned". It's all encoded in a bunch of numbers ("weights") which are hard/impossible for humans to interpret. Much more on this in part 2.
19/ (3) Because they don't operate on formal data or rules, they're able to deal with ambiguous/fuzzy data, like human languages and pictures/art. These were things that were far outside the realm of machines, and that we thought were intrinsically human!
20/ Later we will look at what image generation models like DALL-E and StableDiffusion do. In part 2, we will look at large language models (LLM) like ChatGPT as well.
21/ But I'd like to start a bit earlier in machine learning history and work our way to the more recent findings. I hope it'll show that things are perhaps not as magical as they appear.
22/ One of the first big splashes of machine learning was bayesian filters. Most notably, this was used to filter spam.
23/ On the practical side of things, this was spearheaded by none other than @paulg: paulgraham.com/spam.html
24/ Bayesian spam filtering is based on Bayes' rule of conditional probability: P(A|B) = P(B|A) P(A) / P(B)
(where P = probability, | = "if")
Example: P(spam | viagra) = P(viagra | spam) P(spam) / P(viagra)
25/ To train a bayesian spam filter, you start with a corpus of emails that have been annotated to be spam or not.
26/ From this, you can easily derive:
P(spam) = proportion of mails that are spam
P(viagra) = proportion of mails containing the word "viagra"
P(viagra | spam) = proportion of spams containing the word "viagra"
27/ From there you can combine these values to get P(spam | viagra).
Do this for enough relevant words and expressions that often appear in emails, combine all of them into a consolidated score, and you get a spam score that you can use to classify emails as spam or not!
28/ This is textbook machine learning: starting from a corpus of examples, we used statistical inferences to extract patterns allowing us to perform classification.
29/ From there, neural networks are only a step away!
From a high level, training a neural network entails tweaking a random computation until it gives you the results you want. For instance, accurate spam classification.
30/ How is the computation defined? It typically looks something like the picture below.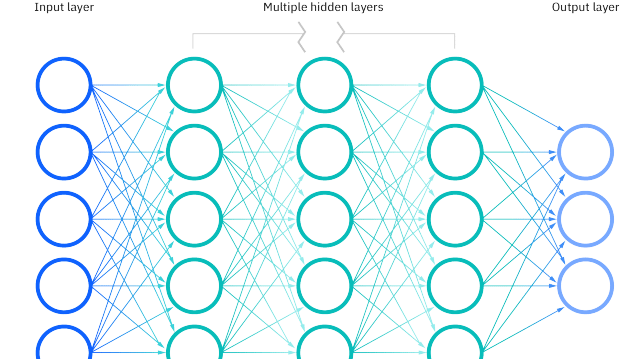
31/ Your input is cut into bits or small numbers and fed into each of the nodes (aka "neurons") in the "input layer". These are connected to all the nodes in a second "hidden" layer.
32/ Each edge between nodes of the two layers is associated with a "weight", such that the value of any node in the second layer is a weighted sum of the values of ALL the nodes in the input layer.
33/ Repeat this process for as many hidden layers as required, and finally for the output layer, which will give your results (e.g. a value between 0 and 1 representing a probability of an email being spam).
34/ You tweak this computation by progressively jiggling the weights around, improving the results as you go.
35/ The process/algorithm that causes the weight to change such that the result improves is called "backpropagation". We won't enter into the details, but it suffices to say it is based on our old friend the gradient descent.
36/ Using this process, we can reconstruct a bayesian-style spam filter. The process is just less direct and more random.
37/ During training, the algorithm will "notice" that as it penalizes the word "viagra" the accuracy increases, and so you'll end up with sensibly the same result.
38/ (A point that will become crucial later: there is no such explicit "noticing", this is all mediated by pretty boring equations.)
39/ Of course, neural networks have many other applications. One that has been huge for more than a decade now is image classification: recognizing pictures of cats, human faces, etc, etc...
40/ The reason why neural networks work so well here is that, unlike text, the features of images are really hard to formalize.
41/ Better to let our random/self-correcting backpropagation algorithm figure out what the features of interest are directly, by operating directly on the pixels of the image!
42/ Using some visualization techniques, we can "peer" into the neurons of a layer to try to see what features they are computing.
The picture below is taken from an article by @stephen_wolfram which I will link to in part 2.
43/ So far, we're not stretching credulity too much. But what about DALL-E and StableDiffusion?
In this case, the network was trained on a corpus of pictures with textual descriptions. What was learned was an association between text and the features of images.
44/ Just like how a classifier develops an "understanding" of the features of a cat, StableDiffusion is able to generate pictures that possess these features.
45/ (Again: this "understanding" is not an explicit concept — you can't query the neural network for its understanding of the concept of a cat. You can only ask it to recognize or generate pictures of cats.)
46/ It all sounds easy when I said it like this, but there are a lot of pesky challenges. It's not that easy to learn what the features of a thing are.
47/ For instance, if your corpus only contains pictures of cows on a backdrop of grass, your neural network is unlikely to recognize a picture of a cow lounging on the beach as a cow.
48/ DALL-E, StableDiffusion, and ChatGPT work around these challenges by using the stupid amount of data that is available on the internet as a corpus.
49/ They still sometimes fail for basically this reason. It's really hard to generate things that are too much outside the box.
e.g. @afk0b has not really been able to generate a "plank anime waifu"
50/ Before we get to ChatGPT, let's quickly mention another cool neural network use: style transfers.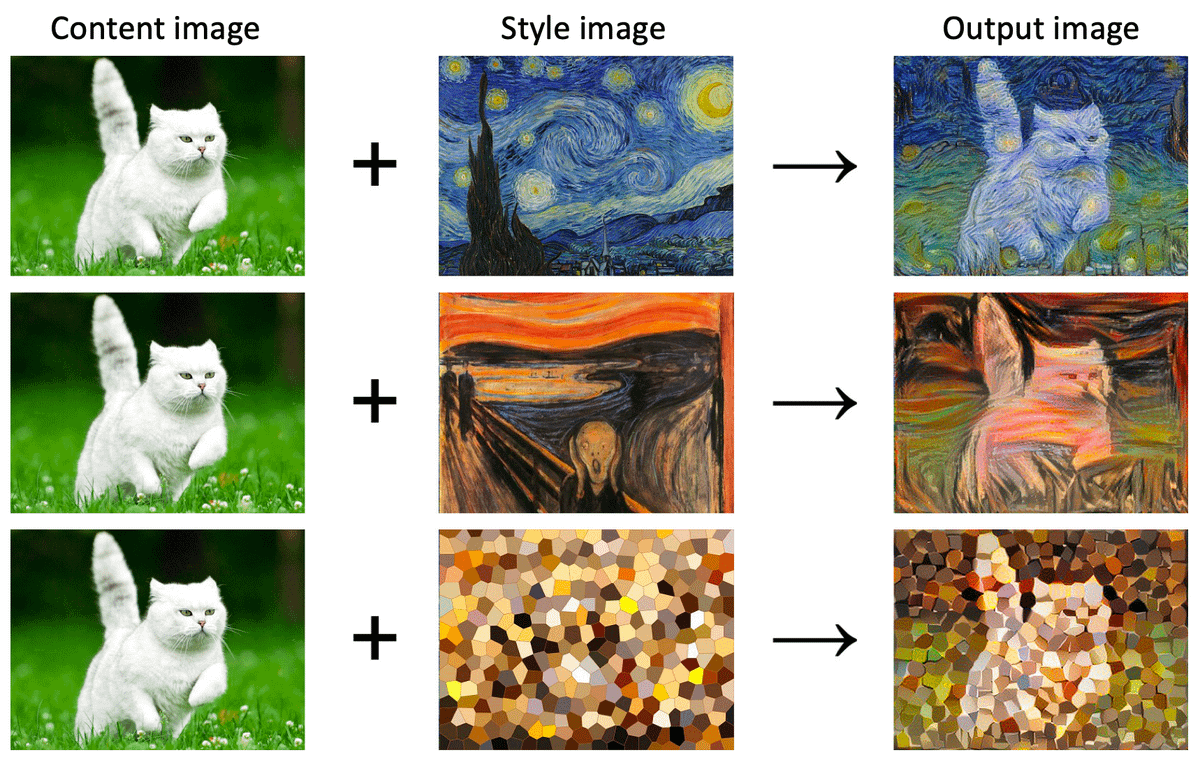
51/ Style transfer can be explained as basically learning a "recipe" for converting an image to a certain style. You could think of it as a series of actions to do in Photoshop, based on the content of the image to transform.
52/ e.g. "identify and preserve shapes outline"
e.g. "smudge the image using an airbrush"
...
(Again, none of that is explicit, it's just a bunch of weights + backpropagation.)
53/ Style transfers are an example of "generative adversarial networks". In this model, we actually train two networks. The network that actually performs the task, and a second "adversarial" network whose goal is to generate additional training data.
54/ The trick is that the adversarial network is trained to "fool" the main network (or in this case, make it produce bad outputs). This creates somewhat of an arm's race: when the main network is fooled, it improves to reduce the chances of this happening again.
55/ The adversarial network, on the other hand, has to become better at fooling the ever-improving main network.
56/ And that's it for today! Tune in sometime next week for part 2, where we will talk about ChatGPT, its capabilities, and speculate about what the future of AI might look like. (Are we all going to ☠️?)

Happy Norswap 🤠🏴☠️✨
@norswap
Perpetual soldier of fortune, occasional internet slacker. Cooking @happychaindevs, I mostly talk about blockchain tech.