











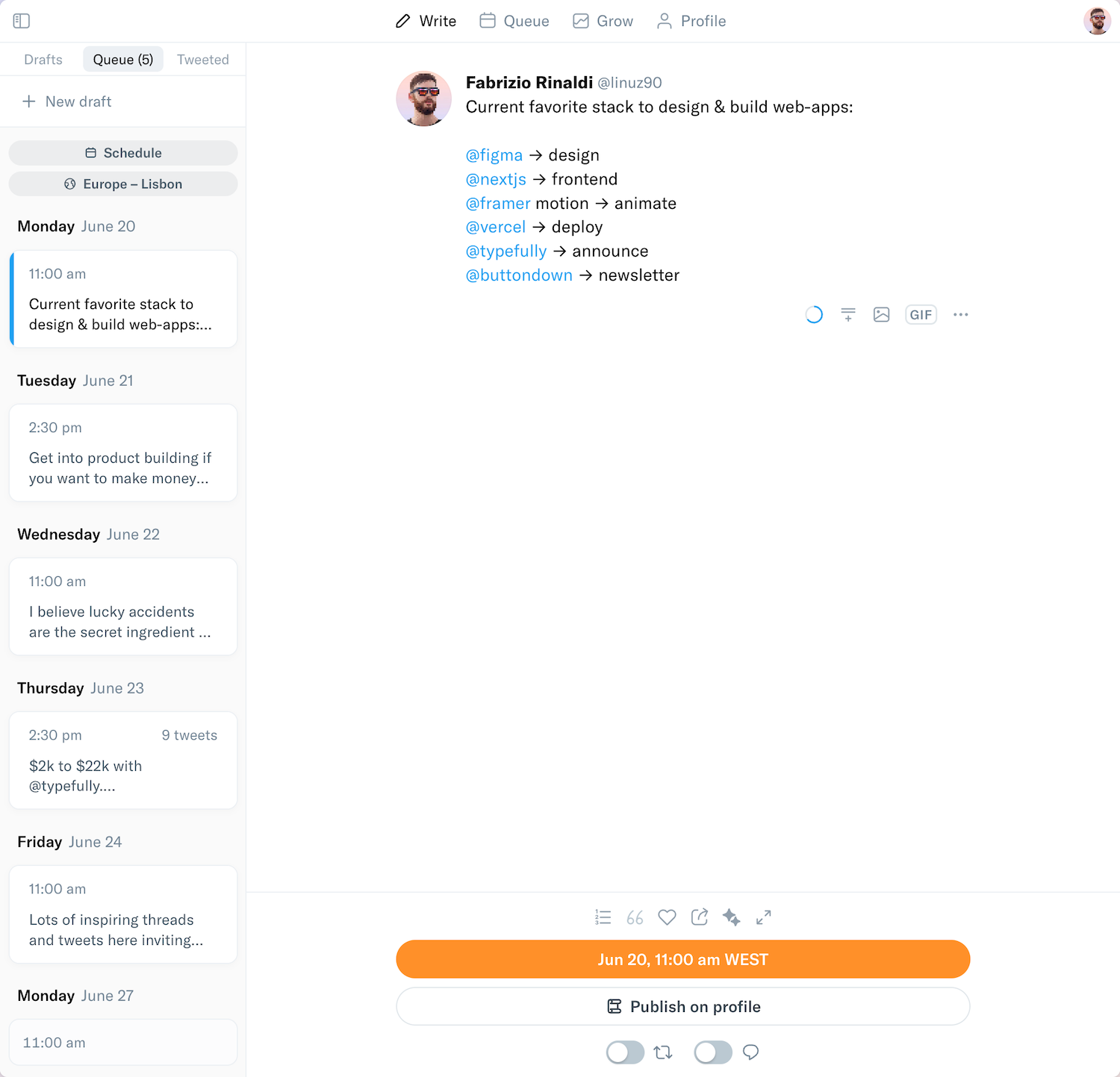










1/15...Data Pipelines are traditionally built with ETL design. But with rising of the modern data stack, new data pipelines are moving towards ELT design.
Let's understand the E, L & T steps, the 2 designs and everything in between: 🧵
2/15...⭐ Extract:
• Fetch data from different data sources.
• It can be from APIs, sensors, events, databases, raw files or any other source that generates data.
• Can be done in batches/streams.
3/15...⭐ Transform:
• Process the extracted data from different sources and make it ready for analytics.
• The goal is to clean the data of any junk/invalid values and to maintain data uniformity.
• Some common transformation models are:
4/15...a. Data Value Unification:
Transform data values from different sources to a single set of values. Example: One source can send city names as codes and the other can send them as the full name of the city.
5/15...b. Data Type and Size Unification:
Transform data types coming from different sources into one data type. Example: Age can come as an int from one source and a string from the other source.
6/15...c. Deduplication:
Remove duplicates from the data coming in from multiple sources.
d. Dropping Columns (Vertical Slicing) :
Removing columns from the data if not required.
7/15...e. Value Based Row-Filtering (Horizontal Scaling):
Based on some business rules, we can filter rows of data for some column values.
f. Correcting known errors:
Correcting known issues and inconsistencies in data.
8/15...⭐ Load:
• Loading the data in a data warehouse or a data mart where it can be used for analytics/BI/ML by the end users.
9/15...I hope you understood the 3 steps in a data pipeline. Let's look at the ELT design pattern now.
10/15...As explained in the image above:
Data is extracted and transformations are done on top of it. Finally, the transformed data is loaded into the final destination.
But a few things to note here:
11/15...1️⃣ Data is stored in a "Staging" layer before any transformations are done on it.
The staging layer can be persistent (new data is added here as and when received) or non-persistent (old data is removed and new data is added every time transformations are done)
12/15...2️⃣ Transformation and loading need to be performed in the same run as the data is stored in a temp staging layer after extraction.
Moving towards ELT design:
13/15...Here, we load data after extraction and perform transformations on it.
1️⃣ There is no staging layer here as the data is directly loaded to the "user-access" layer. (where end-users can access the data)
This is where data lakes can be used for loading the extracted data
14/15...2️⃣ The loading and transformations can be done independently of each other in separate runs.
As with the maturity of the modern data stack, we are seeing a rise in specialized tools for each of the 3 steps in a pipeline.
Ex: Fivetran, Stitch for E and L; dbt for T, etc.
15/15...PS:
Staging Layer is just a name given to a temp warehouse or a data mart that stores intermediate data.
User-Access Layer is a lake/warehouse/mart from where end-users can access the data.
That's it for today! Thanks for reading. 👋