
서비스의 스케일이 커지면서 서버 운영팀은 고민에 빠진다:
"더 큰 서버를 준비할까? 적당한 사이즈의 서버를 여럿 두는 게 더 효율적 일까?"
CPU/Memory 사용 특성, 안전성, 가격 등 여러 요소를 고려해야 하는 복잡한 문제다.
Google SRE 팀의 생각은 어떨까? 요약:
oreilly.com/content/rethinking-task-size-in-sre/
결론부터 시작하면 Google SRE 팀은 적은 수의 큰 서버를 돌리는 것이 더 효율적이였다 한다.
단순하게 접근해보면 돌아가는 서비스는 고정비용 - binary/logging/monitoring 등 - 이 존재하고, 서버가 커질수록 때마다 서비스 전체에 고정비용이 차지하는 비율이 낮아진다.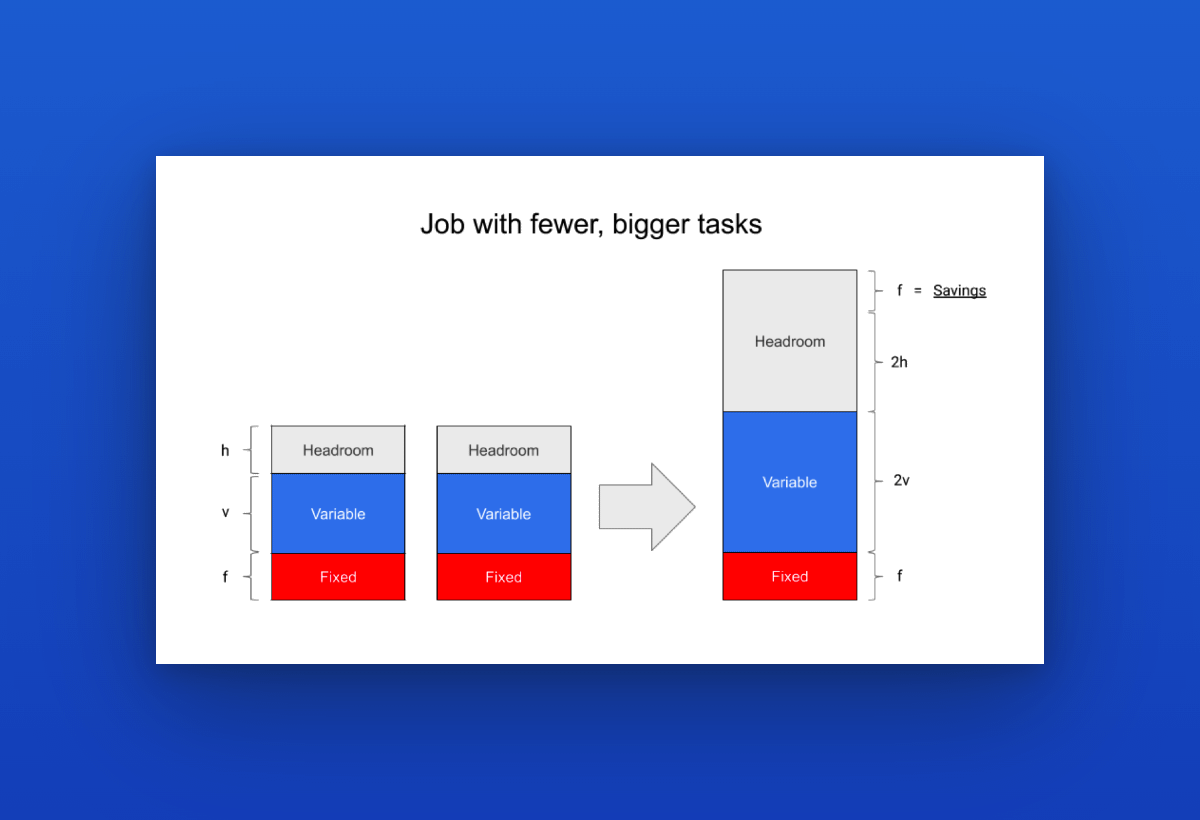
Google SRE 팀은 이 이론을 작은 서비스에 적용해 보았고, 약 25%의 효율성 증가를 보았다.
추가로 몇 가지 생각을 던지는데:
→ CPU는 진화한다. 큰 서버의 효율성은 CPU 업그레이드를 잘 흡수한다.
→ 서비스의 안정성을 고려해 서버를 여럿 둬야하지만, 효율성도 따지는 걸 잊지 말아야 한다.
→ 그때는 맞고 지금은 틀리다. 서비스가 진화하며 서비스의 최적화 세팅도 바뀔 수 있다. 서비스의 효율성은 꾸준히 관찰해야 한다.
→ 때론 효율성과 지연시간을 맞바꿔야 한다. 운영팀은 서비스에 적합한 밸런스를 찾아야 한다.
Google SRE 팀은 이 밸런스를 찾아 나가는 과정에 몇 가지 팁을 전한다:
→ 효율성을 따지는 metric은 Queries-per-Second (QPS) 나누기 CPU. 서비스에 더 알맞은 메트릭이 있다면 (e.g. # job processed 나누기 CPU) 그걸 사용해도 좋다.
→ 효율성을 올리되 req latency/throughput, garbage collection time 같은 다른 metric 지장이 없는지 확인할 것.
→ 새로운 사이즈에 서버가 서비스 운영에 지장이 없도록 부분적으로 오랜 시간 동안 실험해 볼 것.
물론 큰 사이즈의 서버가 항상 맞는 건 아니다:
→ Multi-threaded program은 lock contention 때문에 효율성이 떨어진다.
→ 서비스가 cpu/mem이 아닌 disk, network 의존이 더 클 경우 문제가 발생할 수 있다.
→ K8 사용 시 클러스터 스케줄러가 큰 서버를 찾는데 어려움을 격을 수 있다.