LLMs like GPT-4 & ChatGPT have become mainstream across diverse applications.
Many companies still need to fine-tune these LLMs on their own data to ensure reliable outputs, especially for tasks like classification.
But datasets in many companies are quite noisy...🧵👇
I just read an article that seems super useful for data science teams and developers for fine-tuning LLMs on messy data (aka most real-world data) 🔗👇
kdnuggets.com/2023/04/finetuning-openai-language-models-noisily-labeled-data.html
"Fine-Tuning OpenAI Language Models with Noisily Labeled Data"
Summary of the article👇
You can nowadays use software to auto-find & fix wrong labels in datasets.
Easily produce a better version of your dataset, and then fine-tune your favorite LLM!
This boosted accuracy by 37% for 3 OpenAI LLMs (w/ zero change in the LLM/fine-tuning)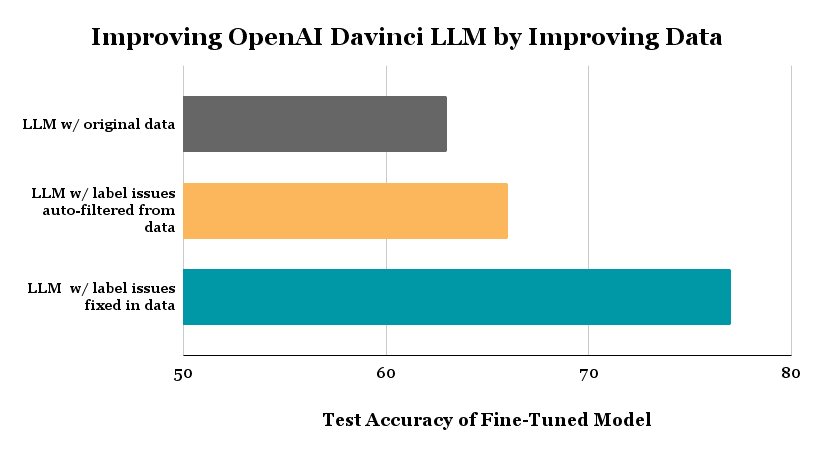
Quickly fix mislabeling + other common issues (like outliers) in your datasets, via the same automated platform used in this article: cleanlab.ai/studio/
This tool's built-in AI scans a dataset for problems. It's easy to fix the detected problems and improve your dataset!

Avi Kumar Talaviya
@avikumart_
Simplifying Data Science and Machine learning for beginners🤖 I share valuable threads & resources on DS/ML/DL @kaggle Master|Python|ML|Data|Analytics|Tech