Boosting algorithm clearly explained...
Boosting algorithms has always been a topic of discussion in the ML community due to their performance and generalization power🤖
let's deep dive into this exciting algo👇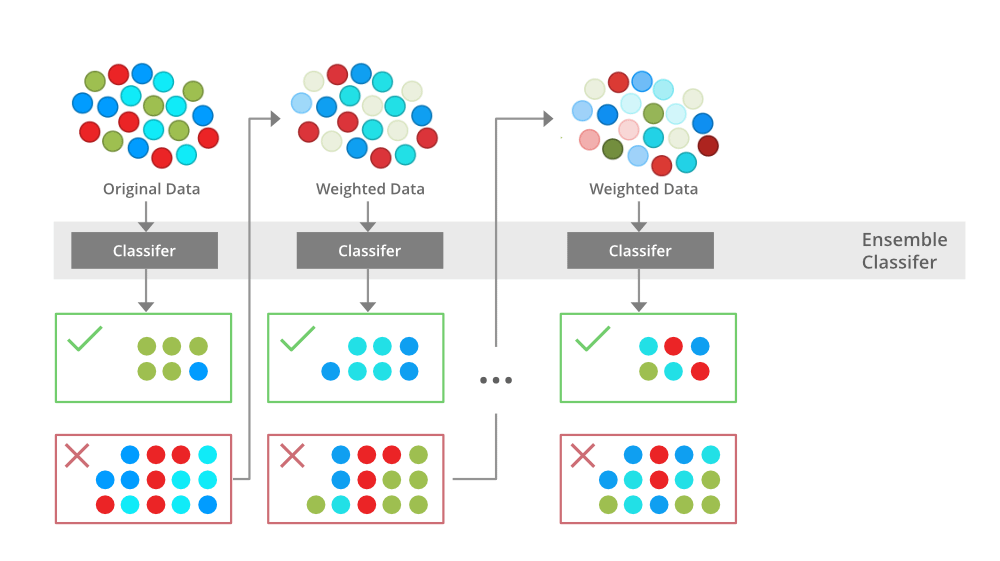
What is boosting technique?
Boosting is a machine learning technique that uses a weak learner to fit the data and sequentially optimizes the error metric of each fit to reduce the error.
Base learners can be decision trees or any other weak learner suitable to the problem
It focuses on improving the model's performance by giving more weight to the misclassified samples in each iteration.
The primary idea behind boosting is to iteratively train new models that correct the errors of the previous ones.
Types of boosting algorithms
There are two major boosting algorithms 1) Adaptive boosting and 2) Gradient descent based boosting algos
Most widely used boosting algorithms:
1) Ada Boost
2) Gradient boosting
4) XGBoost
5) LightGBM
6) CatBoost
Code example of Ada boosting algorithm
Let's look the code example of ada boosting algorithm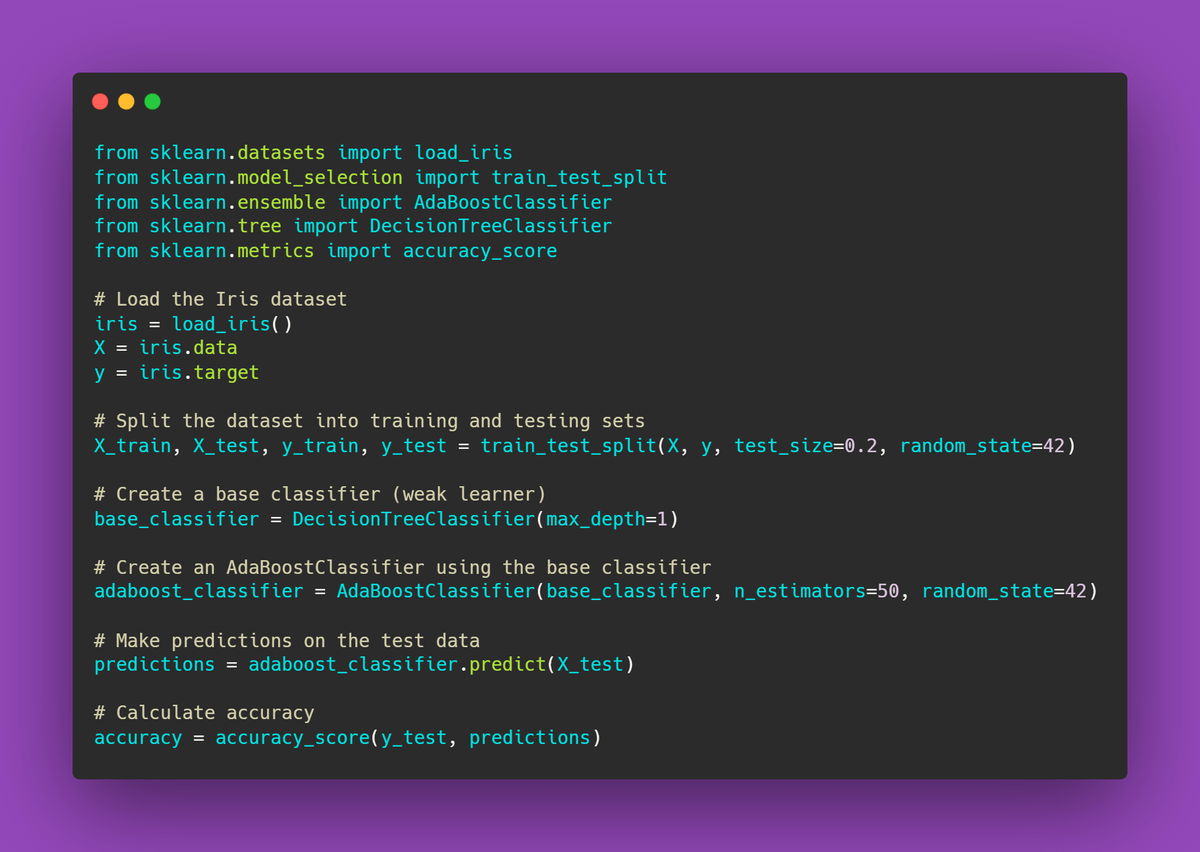
There are other versions like "Hist Gradient Boosting" which fall under the type do gradient boosting algorithms.
It is used in datasets where samples are greater than 10,000 and features are mostly numerical.
Boosting techniques are famous in classical ML due to their performance and feature reach libraries along with custom solutions available
Hyperparameters are also key factors in building the best predictive models, you can learn this from documentation
scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble
Check out some of my notebooks on ml modeling using these techniques👇
kaggle.com/avikumart/code
BONUS: Check out my latest article on custom Q&A application development using OpenAI, LangChain and Pinecone published on Analytics Vidhya👇
analyticsvidhya.com/blog/2023/08/qa-applications/

Avi Kumar Talaviya
@avikumart_
Simplifying Data Science and Machine learning for beginners🤖 I share valuable threads & resources on DS/ML/DL @kaggle Master|Python|ML|Data|Analytics|Tech








