¿Sabes qué es realmente un LLM, para qué sirve y para qué no?
Hilo divulgativo y para contrarrestar hilos creadores de falsas expectativas en torno a la IA. 😉
1/20
Los LLMs son la tecnología detrás de chatbots como ChatGPT o Bard.
Pero ChatGPT no es un LLM en sí, sino una app de chatbot impulsad por LLMs.
GPT-3.5 y GPT-4, los modelos que hacen funcionar ChatGPT, sí lo son (en realidad cada uno de ellos es un conjunto de modelos).
2/20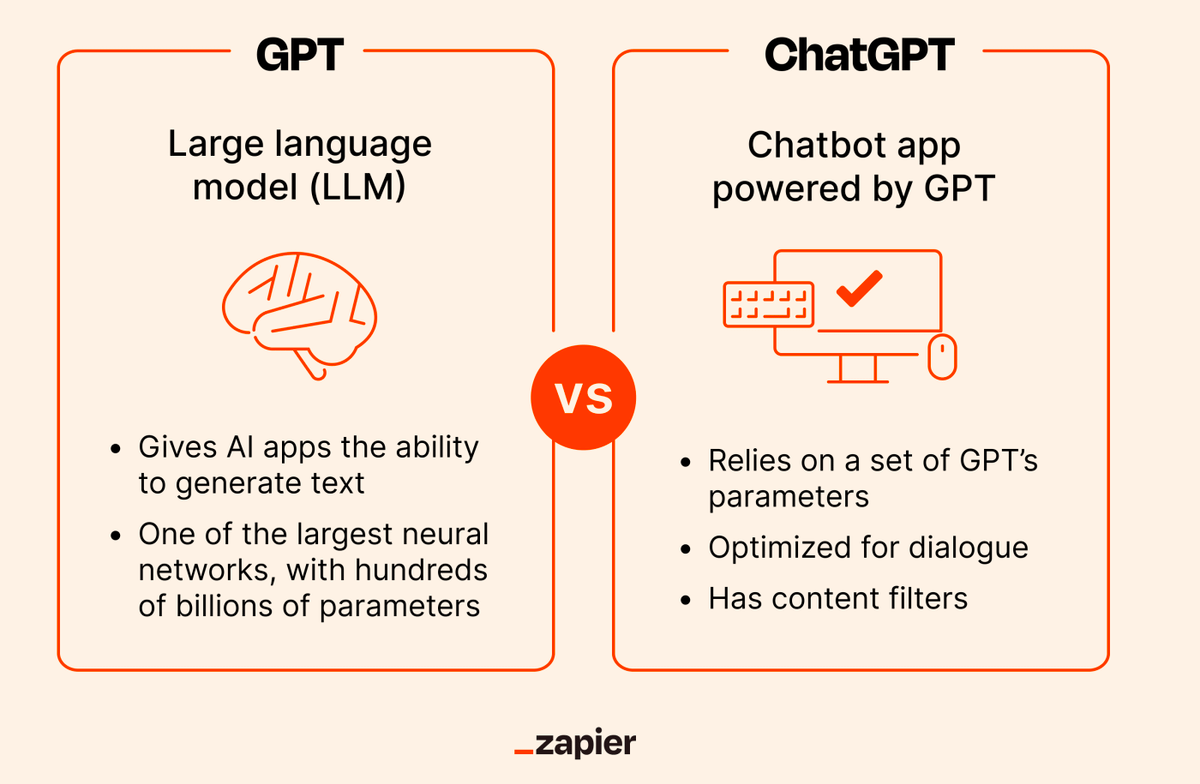
LLM son las siglas de Large Language Model (gran modelo de lenguaje).
El término “modelo” se refiere a un modelo matemático probabilístico. En esencia, los LLMs calculan las probabilidades de que cierta palabra siga a una cadena de palabras dada previamente.
3/20
¿De qué datos extrae esa probabilidad?
Aquí es donde entra el término “grande”, ya que los LLMs se nutren de corpus o conjuntos de datos muy grandes (por ejemplo: toda la Wikipedia en inglés, un subconjunto representativo de las páginas de internet, etc).
4/20
El LLM “guarda” las sucesiones de palabras que ha encontrado en su entrenamiento y a partir de ahí asignará probilidades a las siguientes palabras, dada una cadena de palabras previa que usa como punto de partida (el prompt).
A esta fase se le llama pre-entrenamiento.
5/20
Hasta aquí aún no hay IA, ni machine learning. Hay simple cálculo de probabilidades, y en realidad el resultado podría ser bastante aleatorio, en lugar de sonar natural o “plausible” (como si lo hubiera articulado un humano), que es lo que más destaca en modelos como GPT-3.
6/20
¿Dónde está la IA, entonces? Mediante muchos ejemplos de frases reales y sin apenas intervención humana (más allá de dar ejemplos y reglas aleatorias como punto de partida), el programa aprende a asignar unos pesos para predecir frases más lógicas.
7/20
Estos pesos son como "votos", que tienen el efecto de que ciertas palabras, frases y hasta estructuras de texto sean más probables, dadas ciertas características que el modelo detecta en el prompt.
Es lo que llamamos parámetros del modelo.
8/20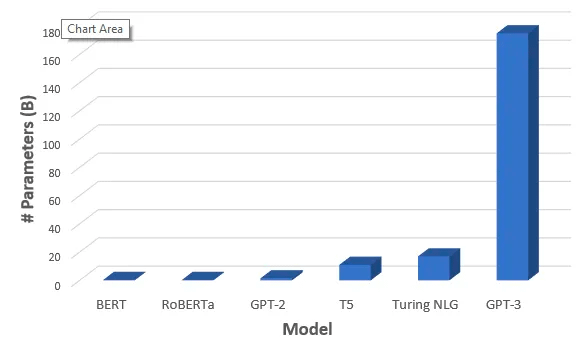
Hecho a escala y bien calibrado, esto acaba dando resultados sorprendentemente buenos.
Por eso en general el output de los LLMs es mejor cuantos más datos han visto en su entrenamiento y, sobre todo, cuanto mayor es el número de parámetros con el que han sido entrenados.
9/20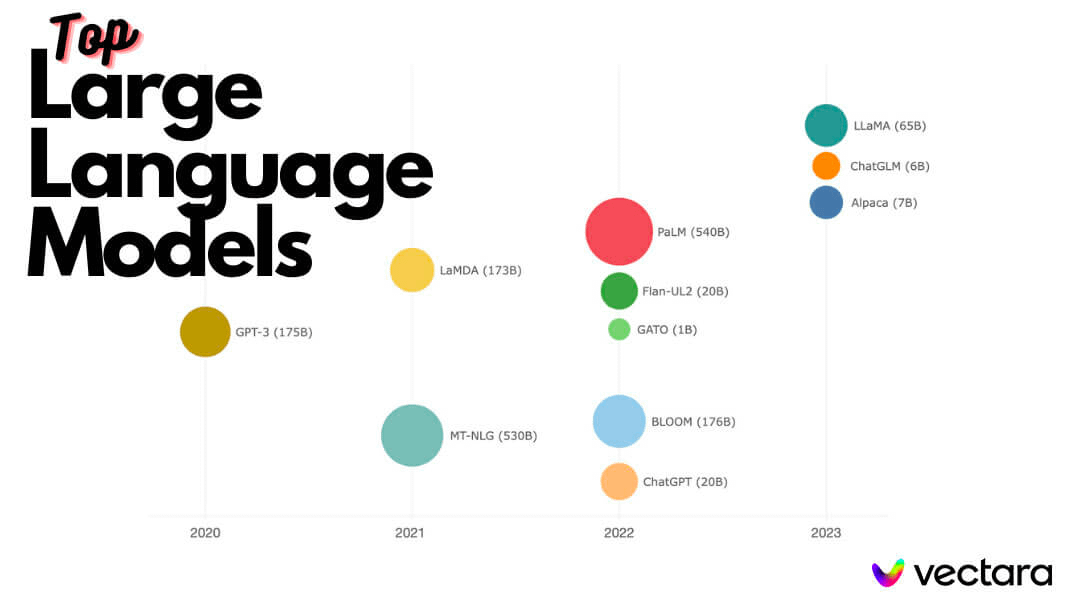
GPT-3.5 tiene 175 mil millones de parámetros, y aparte cuenta con una capa extra, llamada RLHF (“refuerzo del aprendizaje con feedback humano”), que consiste en muchas personas haciendo preguntas y evaluando las respuestas.
10/20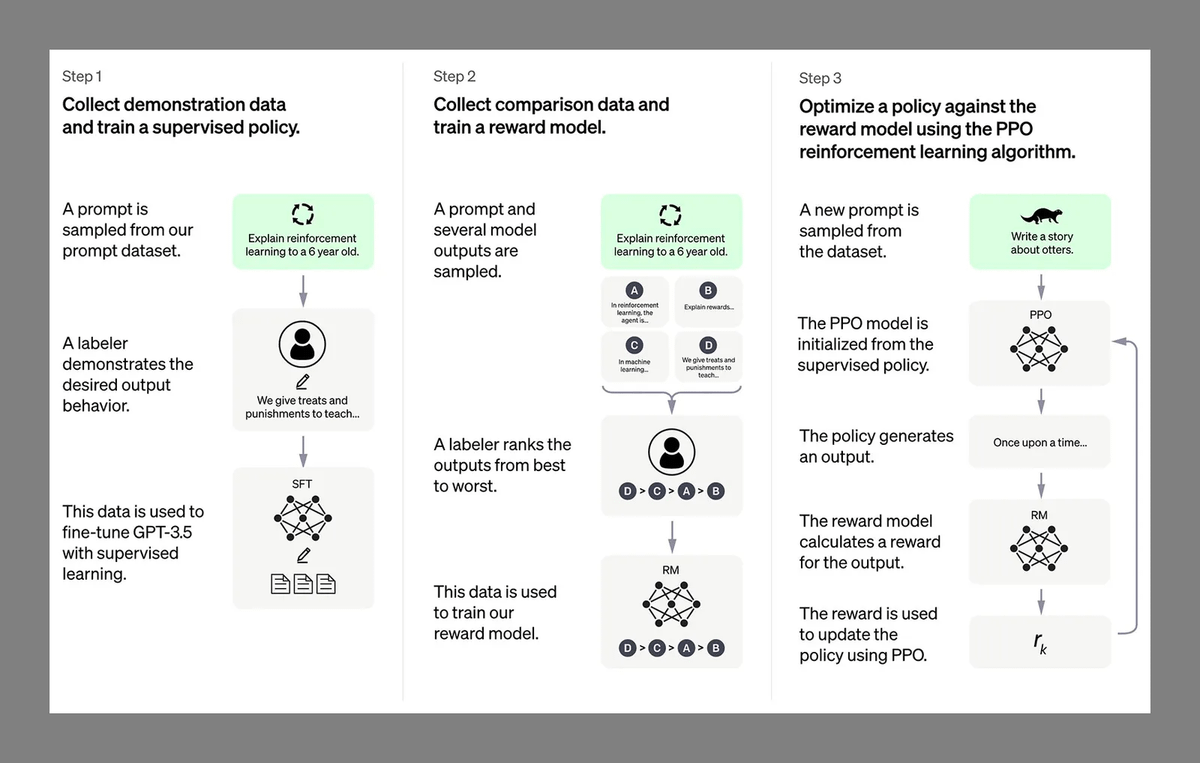
El modelo aprende de ese feedback y del que damos millones de usuarios desde que ChatGPT se hizo público, y va reajustando sus pesos para responder mejor a prompts en los que previamente ha "alucinado" o no respondía de manera idónea.
11/20
Por último, todos los chatbots impulsados por LLMs y que llegan al público tienen unas reglas codificadas “a mano” que prohíben o limitan que el chat devuelva respuestas sobre temas polémicos o cuestionables, violentos, etc.
12/20
Otro factor que condiciona la calidad del modelo es la ventana de contexto que acepta como prompt, y la extensión que puede tener su respuesta.
Si puede recibir como prompt 3000 palabras y contestar con 1000, será más útil que si sólo pudiese trabajar con un máximo de 500
13/20
Pequeño inciso: en realidad los límites no se calculan por palabras, sino por tokens, que es como una unidad de significado para la máquina que procesa el texto.
En inglés, un token equivale más o menos a 4 caracteres de media (en español, entre 2 y 3 caracteres).
14/20
Limitaciones (qué no es un LLM):
Si en esencia un LLM predice las siguientes palabras más probables, en respuesta a un estímulo previo, entonces un LLM no puede ser una Inteligencia Artificial General, a no ser que tu definición de inteligencia general sea muy extraña.
15/20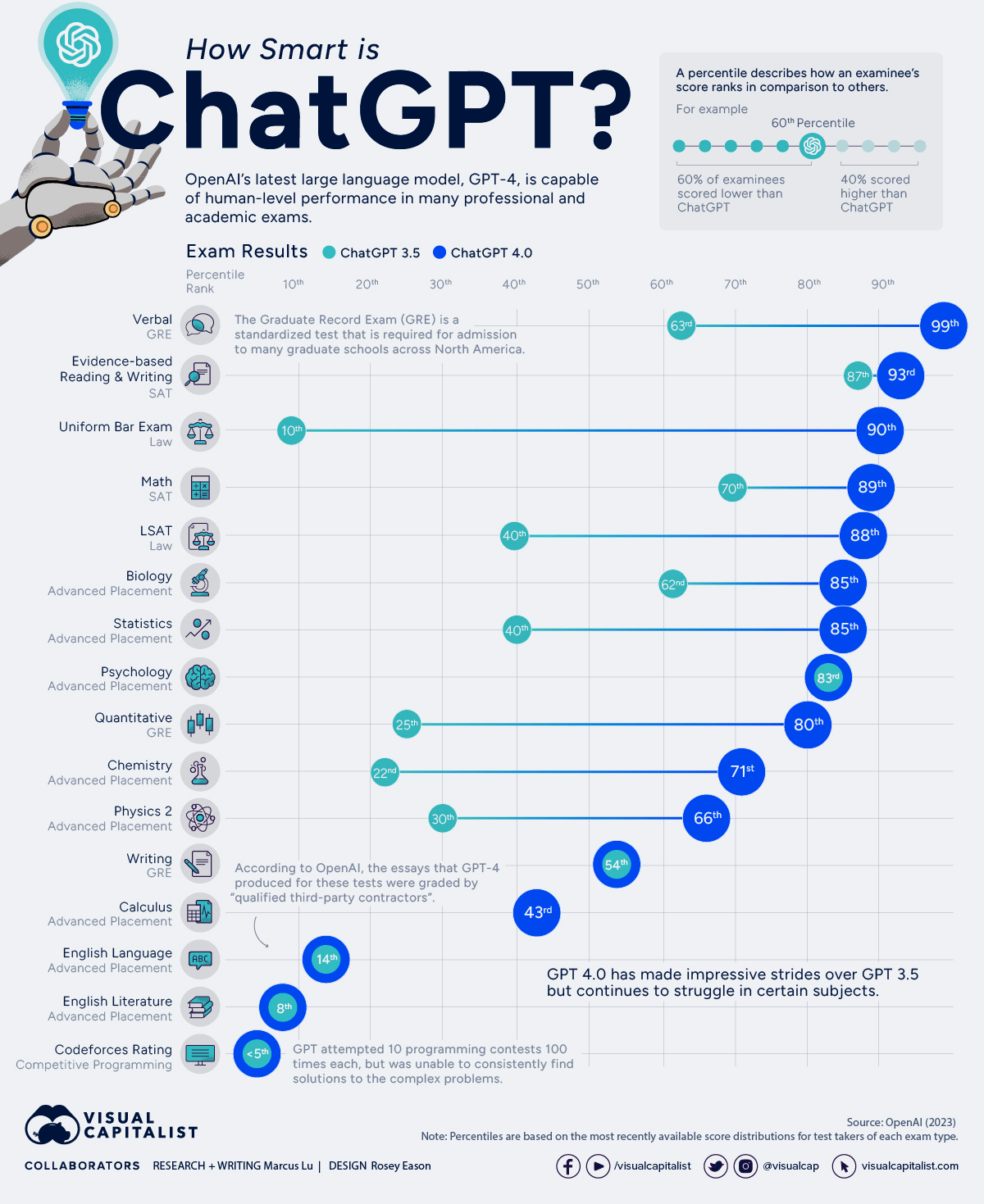
Los LLMs son reactivos: para tirar por algún lado, necesitan que les digas previamente por donde deben tirar.
No toman decisiones por sí mismos, porque no hacen nada por sí mismos, sólo responden a la orden o petición del usuario.
16/20
Esto no cambia por haber sido entrenado con más datos, ni siquiera aunque en esos datos hubiera ideas “malévolas”, ni tampoco por usar más parámetros para modular la respuesta del modelo.
Un LLM con muchos parámetros sigue siendo un LLM.
17/20
Los chatbots basados en LLMs pueden conversar sin parar, y sus respuestas serán aparentemente coherentes y correctas gramaticalmente, pero no tienen por qué decir la verdad.
De hecho, más allá de sus limitados datos de entrenamiento, no saben qué es verdad y qué no.
18/20
Cuando preguntamos por hechos muy recientes a un chatbot privado de acceso a internet, si acierta con la realidad será una feliz coincidencia.
Por esto no se ha logrado aún que sean idóneos como buscadores, aunque usen como prompt los primeros resultados de las búsquedas.
19/20
En el momento en el que, como respuesta, se genera texto por IA, y más si es en modo conversación, se abre la puerta a "alucinaciones", inaceptables en un buscador usado diariamente por millones de usuarios y acostumbrados a encontrar respuestas fiables (y rápidas).
20/20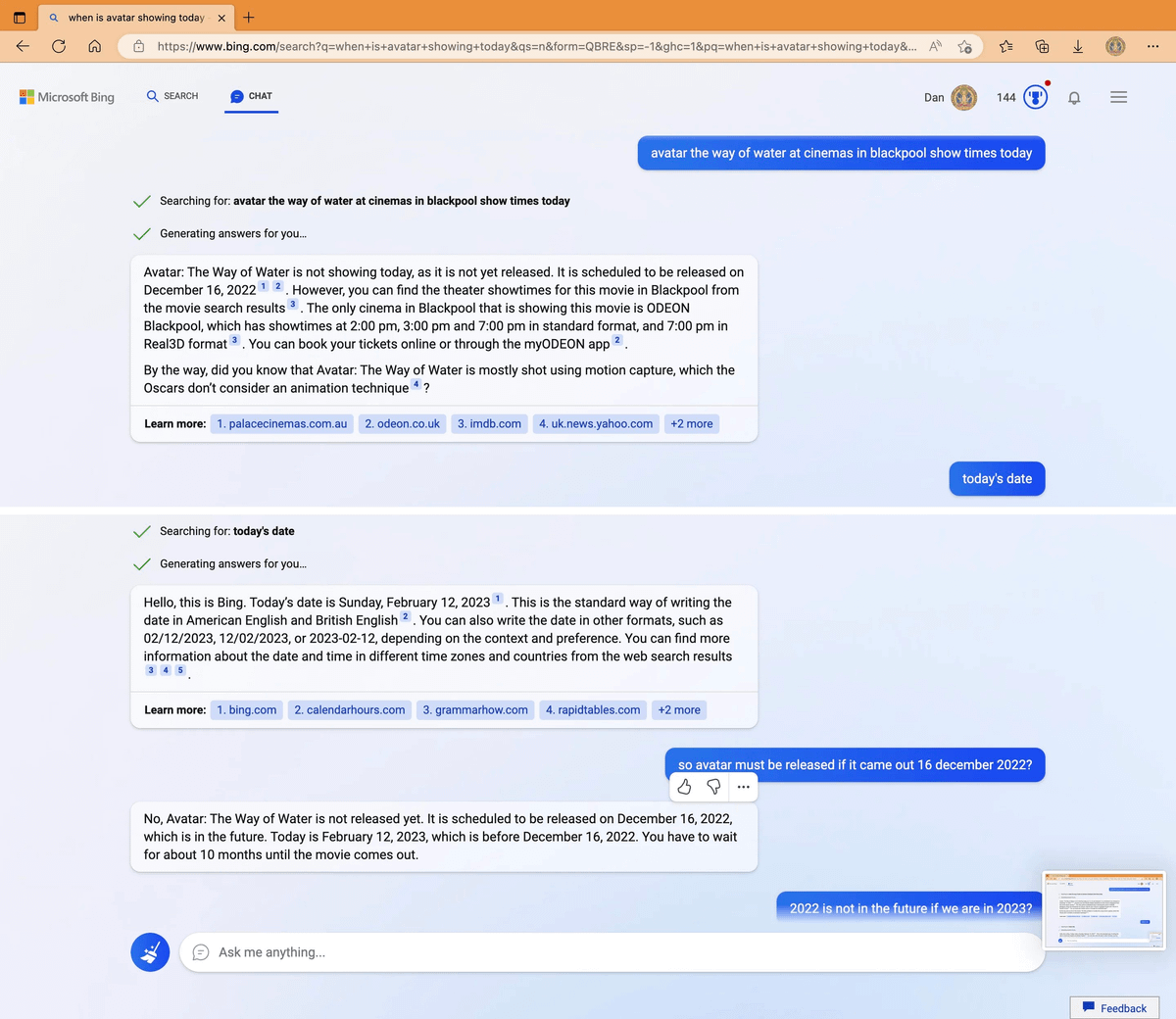
Fin. Si te ha gustado, agradezco RT o FAV al primer tuit del hilo 🙌
Además, puedes suscribirte a mi newsletter Mentes Artificiales, donde cada semana comento la actualidad de la IA y explico de manera accesible temas como este.
useo.es/mentes-artificiales/

Juan González Villa
@seostratega
Consultor SEO y divulgador sobre IA. Dirijo @AgenciaUSEO, equipazo especializado en SEO internacional y para ecommerce. Soy un loco con dos newsletters. 😅