Venga, hilo para resumir y explicar cómo funciona el algoritmo de recomendación de Twitter, cuyo código se hizo público ayer.
¿Cómo se deciden qué tuits te aparecen recomendados en la pestaña Para ti, y en qué orden? Te lo cuento en 15 tuits:
1/15 🧵
Los datos que alimentan al sistema salen de 3 fuentes:
• El Follow Graph (quién sigue a quién)
• Las métricas de interacción de los tuits
• Otros datos de usuarios (como por ejemplo a quién has bloqueado / muteado, qué contenidos te interesan, etc).
2/15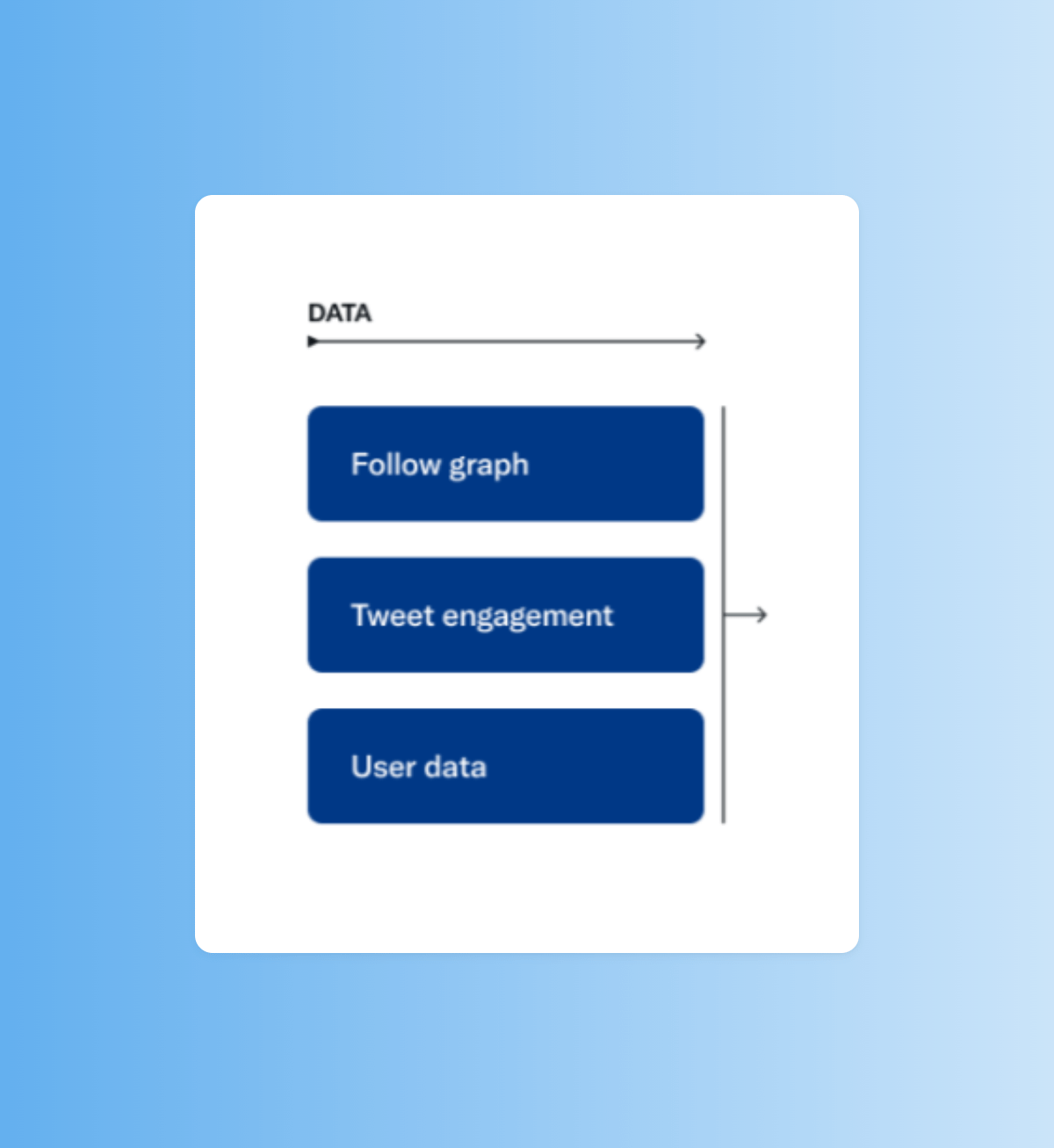
Sobre esta base, se aplican una serie de cálculos, de los que salen los "tuits candidatos".
Uno de estos cálculos es el RealGraph, un modelo que calcula la probabilidad de que te interese lo publicado por cierto usuario (incluso si nunca antes habéis interactuado).
3/15
Otro es el TweepCred, que es en realidad un PageRank (algoritmo ideado por Google para rankear páginas web).
Según esto, eres más influyente o tienes más autoridad, cuanto más influyentes son los usuarios que te siguen.
4/15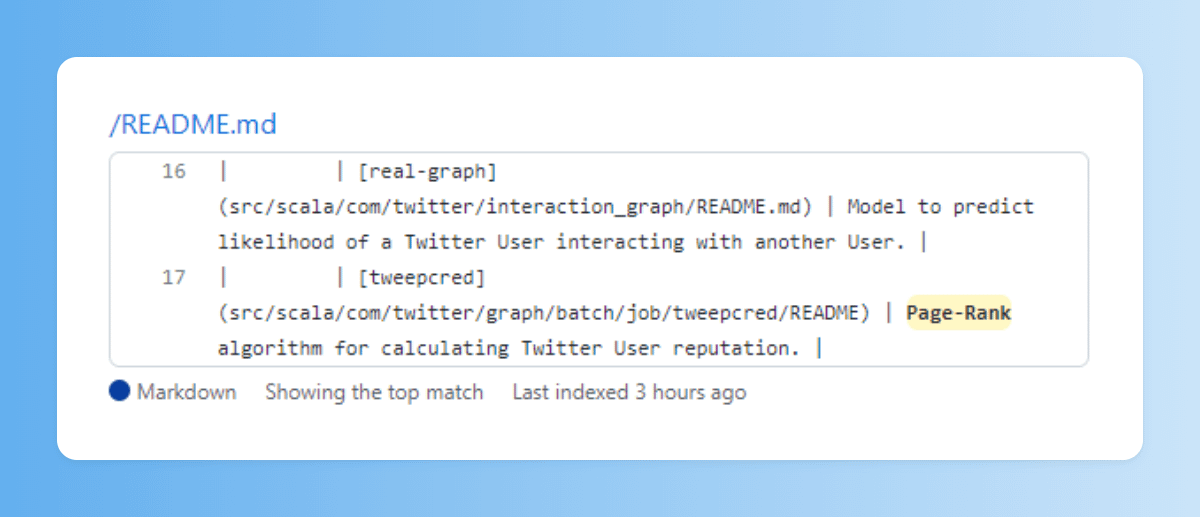
Hechos los cálculos, tendremos como candidatos unos 1500 tuits, de los cuales un 50% salen de las cuentas que sigues, y un 50% de cuentas a las que no (aproximadamente, esta proporción varía para cada usuario).
5/15
Para decidir qué tuits serán candidatos de fuera de tu red usan dos métodos: el Social Graph y Embedding Spaces.
Social Graph es una forma de buscar usuarios afines a ti: tuits con los que han interactuado usuarios que sigues y usuarios con gustos similares a los tuyos.
6/15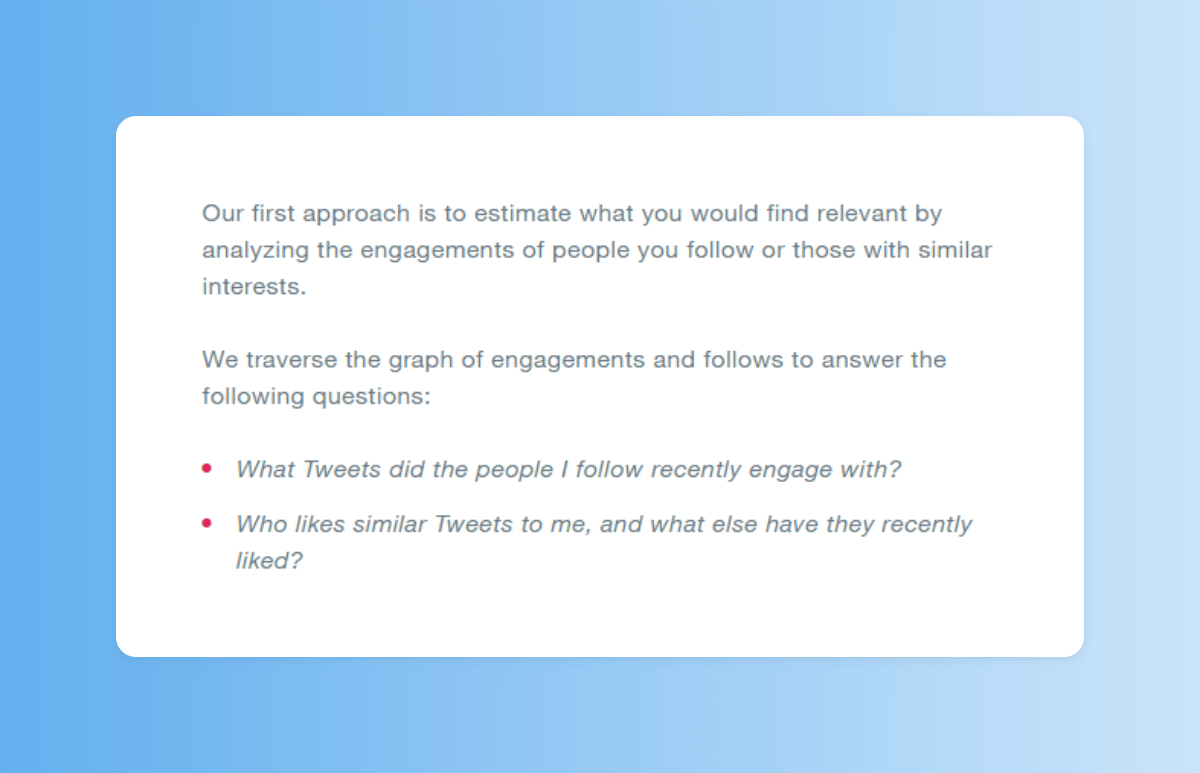
Los Embedding Spaces son más complejos, pero también buscan encontrar tuits y usuarios afines a tus intereses.
Embedding es transformar en números cadenas de texto (por ej. tuits). Hecho esto, se puede determinar el grado de similaridad entre dos tuits o conjuntos de tuits
7/15
SimClusters es un embedding space que crea "comunidades invisibles" dentro de Twitter, agrupadas en torno a una serie de usuarios influyentes.
Hay 145.000 comunidades, y se actualizan cada 3 semanas. Tanto usuarios como tuits pueden pertenecer a más de una comunidad.
8/15
Las comunidades pueden tener entre unos pocos miles de usuarios y varios cientos de millones.
Cuanto más le gusta un tuit a los usuarios de una comunidad, más asociado con la comunidad estará ese tuit.
9/15
Bien. Tenemos 1500 tuits candidatos y llega el momento de ordenarlos en tu pestaña For You.
De esto se encarga una red neuronal de 48 millones de parámetros, continuamente entrenada en datos de interacción de tuits, para obtener el mejor resultado de interacción posible.
10/15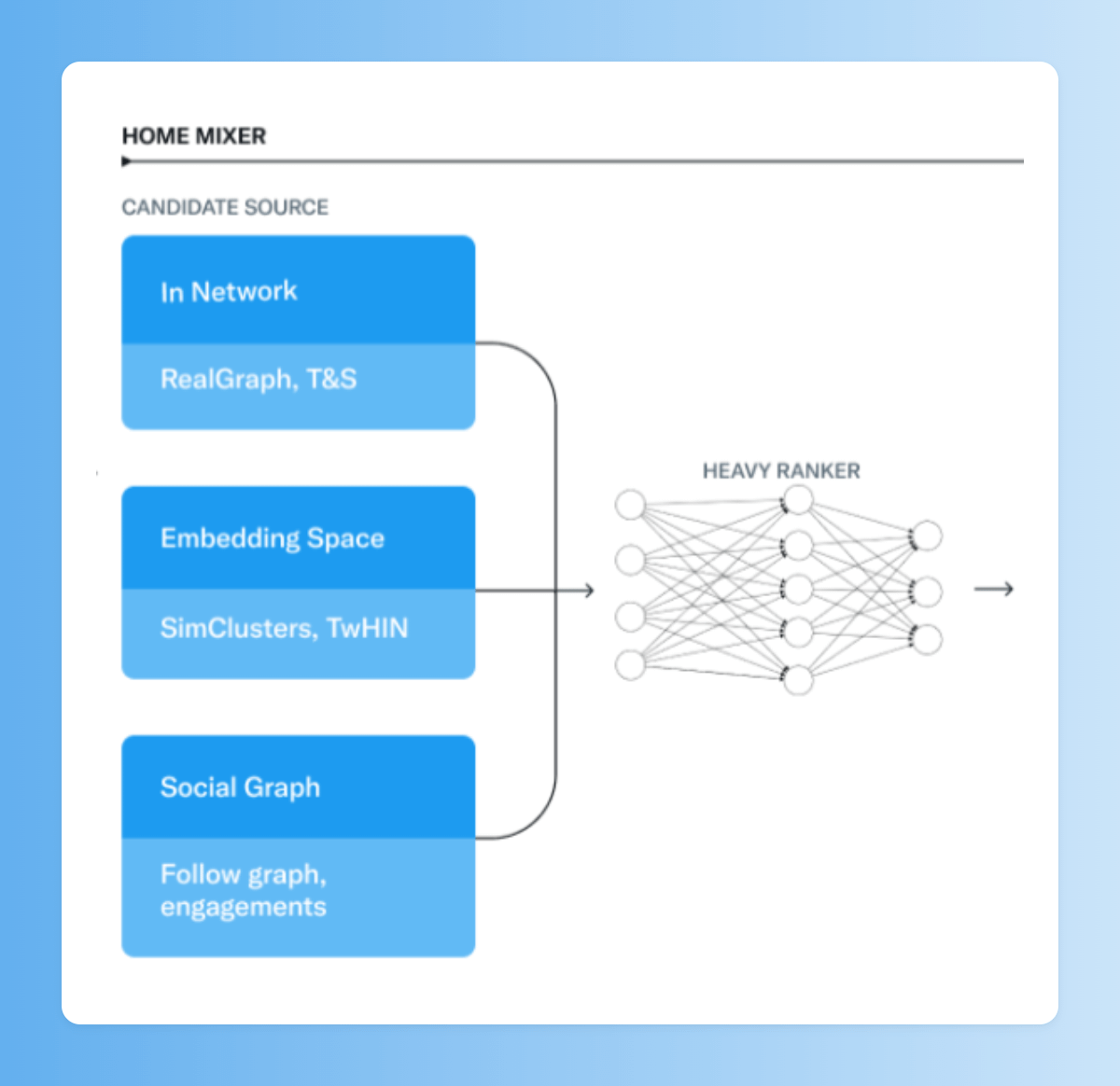
Es decir, la red neuronal tiene la misión de colocar más arriba los tuits que, según los datos observados anteriormente, tienen más posibilidades de generar interacciones.
Esto es habitual en los algoritmos de recomendación de cualquier red (Facebook, YouTube, Discover).
11/15
Tras esto, queda filtrar/modificar de acuerdo a criterios especiales, como por ejemplo:
• Extraer de tu feed temas que has expresado que no te interesan, y tuits de usuarios a los que has bloqueado o muteado
• Evitar que el mismo autor tenga demasiados tuits seguidos
12/15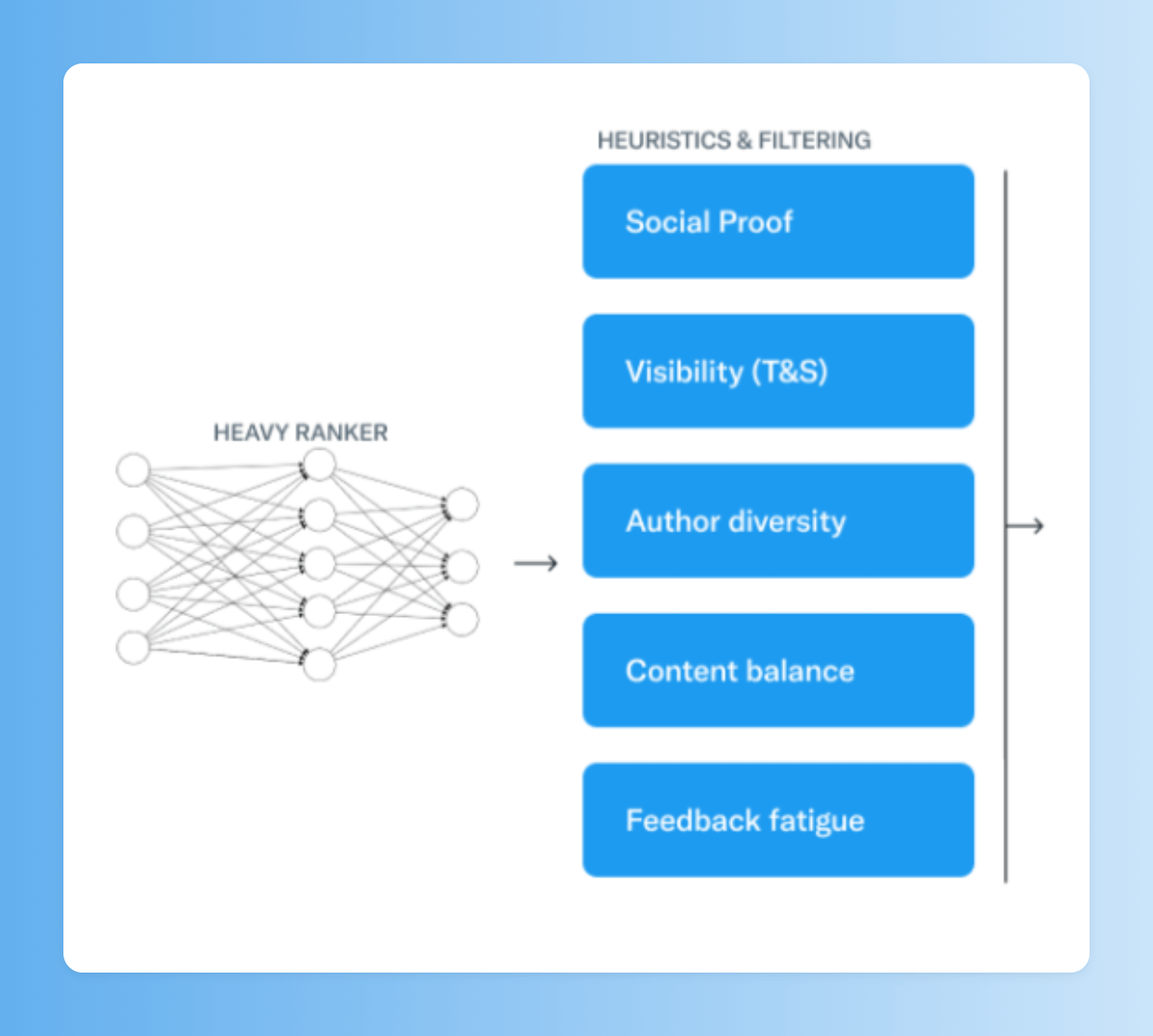
• Excluir tuits en los que no hay una relación de segundo grado contigo (alguien a quien sigues debe seguir al autor del tuit, o haber interactuado con el tuit)
• Añadir el tuit original cuando se trata de una respuesta o conversación
13/15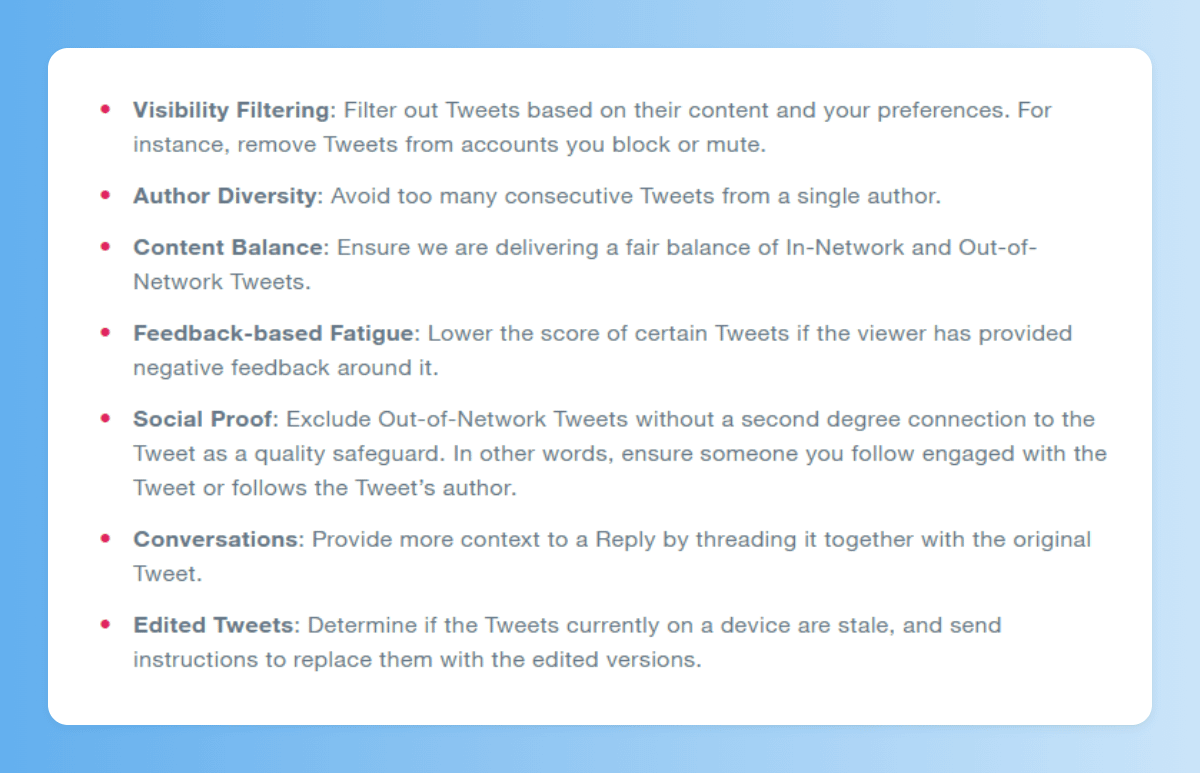
Ya sólo queda intercalar otros tipos de contenido, como anuncios o recomendaciones para seguir a otros usuarios, y la cadena de tuits está lista para servirse.
Esto sucede unos 5000 millones de veces al día, y todo el proceso se ejecuta en un segundo y medio. 🙀
14/15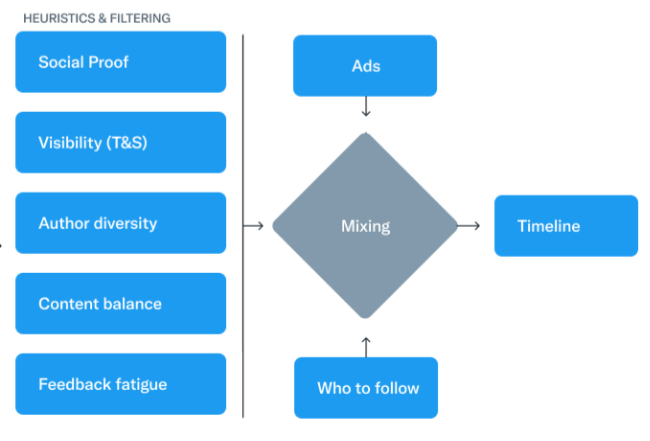
Aquí tienes un esquema del proceso completo.
¿Qué te ha parecido? ¿Crees que podría ser manipulable (más allá de "fusilar" tuits que han tenido buen engagement, o de solicitar directamente interacción con el tuit)?
15/15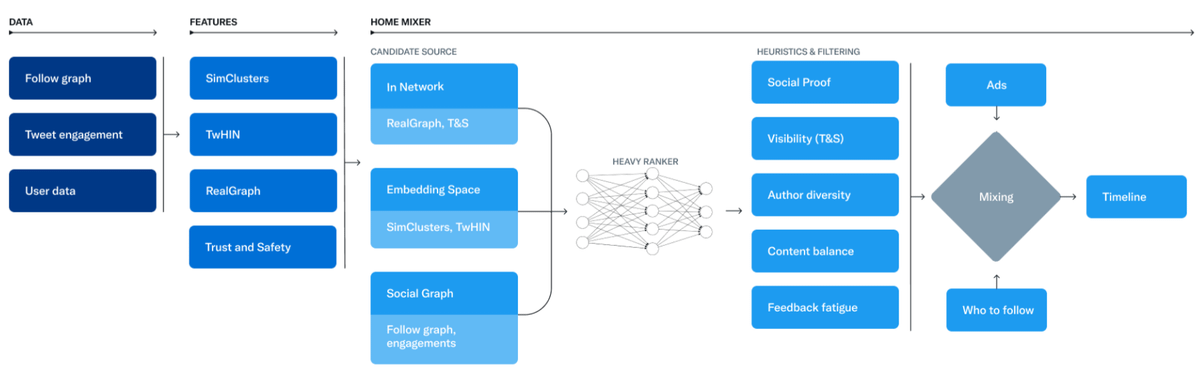
PD: Si te ha gustado, sólo te pido que le des un poco de amor al primer tuit del hilo. 😉
Y te invito a suscribirte a mi newsletter semanal, donde trato de explicar de manera sencilla todo lo que rodea a la IA: useo.es/mentes-artificiales/

Juan González Villa
@seostratega
Consultor SEO y divulgador sobre IA. Dirijo @AgenciaUSEO, equipazo especializado en SEO internacional y para ecommerce. Soy un loco con dos newsletters. 😅