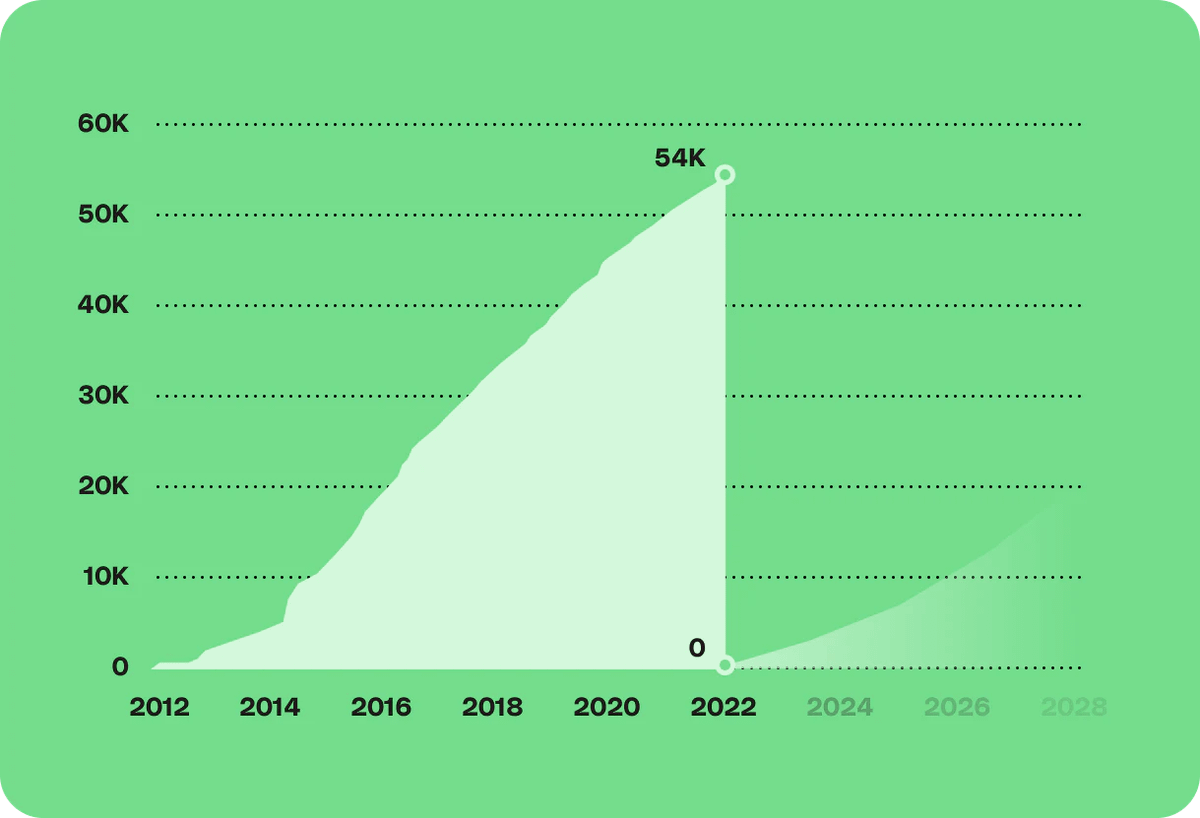
Another data loss related yesterday, human error vs UX features this time. A popular project on Github lost information. Their complaint comes in a form of a very positive blog post.
↓
“Lesson #2: Database design
Use soft-deletes. People are human and they make mistakes. For hard-deletes, delay the process.” — @jakubroztocil at 📄How we lost 54k GitHub stars in @httpie blog post
↓
soft-deletes are an interesting and challenging technique. I personally prefer a balance like in a "recycle bin approach", to keep deleted records for some time, but maybe it all depends on the specific application.
↓
I've seen implementations based not on marking the records but moving them to a different table which makes a lot of sense to me, bc all the potential rules you can skip like replication, caching, log shipping, etc. Also easing the application of new ones like retention.
↓
👀 “While the author clearly feels bad about the fact that they've lost his community and that GitHub didn't restore it”…“they're also focusing towards the future and using their personal xp as a parable all of us can learn from.”—vaishnavsm at HN twitter.com/jakubroztocil/status/1514735329323933703
↓
Personally, I think GitHub makes it pretty hard to make this mistake already, so agreed with making sure you're not on autopilot when taking potentially dangerous actions. (with credits to cmeacham98 at HN)
↓
Anyway, also believe expecting users to stop making mistakes is much less effective than improving the software that amplifies those mistakes into irreversible impacts. Of course, is a very unselfish thought. (with credits to wpietri at HN)
↓
Read the issue with lessons and reflections from @jakubroztocil and @httpie at httpie.io/blog/stardust
↓
You can check the HN discussion
news.ycombinator.com/item?id=31033758 at hacker.news.
🔥1617 points, +500 comments in 17 hours
news.ycombinator.com/item?id=31033758
↓
Back to our #DataTalk and the soft delete pattern, we have a lot of options to seize on, with more or less use of the technologies' offerings at each layer and stack. I collected some tweets for us:
twitter.com/nilsandrey/timelines/1514993095959617537
▮

Nils
@nilsandrey
🇨🇺 🇨🇦 Software developer, I like sports and movies. Family first. My friends are part of my world.