I'm dealing with a ton of database records for traits.xyz
Over 100,000 records for an average collection. Some are in the millions.
Here's some Rails/Postgres tricks I've learned to deal with:
✂️ Split up data processing into small, separate background jobs
This helps prevent running out of memory. It also makes it easier to see which parts are slow (i.e. which jobs)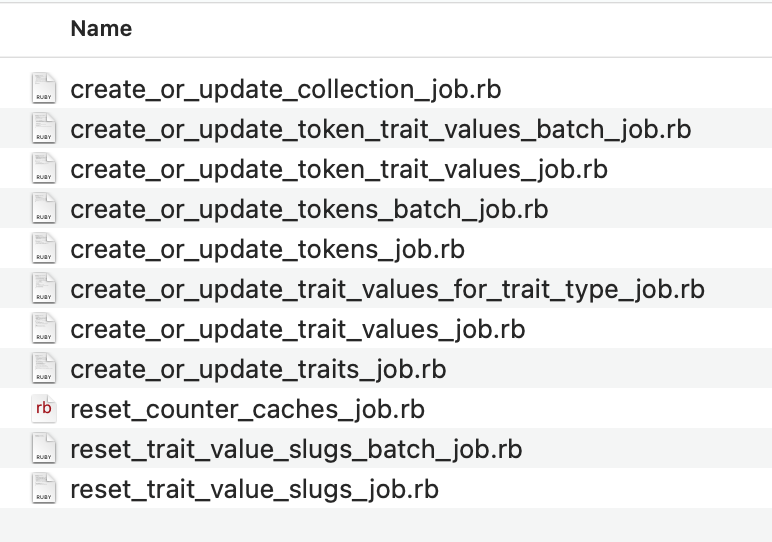
🎟 But be careful making the jobs too small
It's usually faster to SELECT say 100 records at once, than doing 100 individual SELECTs in separate jobs.
♻️ Don't be afraid to duplicate some data
It's a best practice to have no duplicate data. But going through a has_many association over and over again can be slow. Sometimes it's better to just duplicate foreign key on those nested records.
3️⃣ Be careful with counter caches
Counter caches are great way to increase SELECT performance, as you can get an association count without additional SELECTs.
But be aware it runs an UPDATE after each INSERT. If you insert 10,000 records, that's 10,000 additional UPDATEs.
The solution is to create your own counter cache that you only calculate _after_ all the rows have been inserted.
⛏ Select only what you need
Sometimes it's okay to be picky. When dealing with a lot of data leverage ActiveRecord's `select` to only SELECT the columns you actually need to get the job done. This is especially helpful when dealing with large records that have lots of data.
🪶 Pluck it, we'll do it live
Related to the above: If you only need a few columns, it's often better to use .pluck(:column_name) which will return an array rather than instantiating a bunch of objects.
You do lose some of the niceties of working with an object however.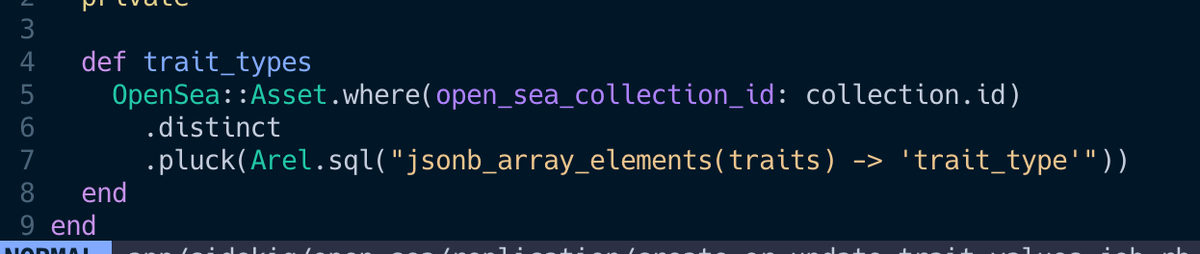
🙌 Use upsert_all
If you can get away with do a big INSERT over many many small ones.
blog.testdouble.com/posts/2020-04-09-speed-up-your-rails-app-with-upsert_all/#notes--caveats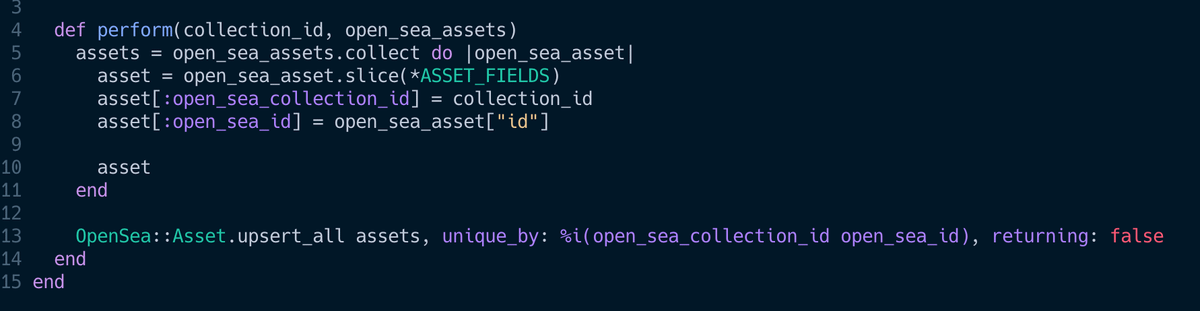
🫗 Use ;nil in Rails console
SSH'ing into your server and processing data? Often returning the results to your computer is the slowest part.
When running a command that returns a bunch of records, add ;nil at the end of it to prevent all that data from being sent back to you.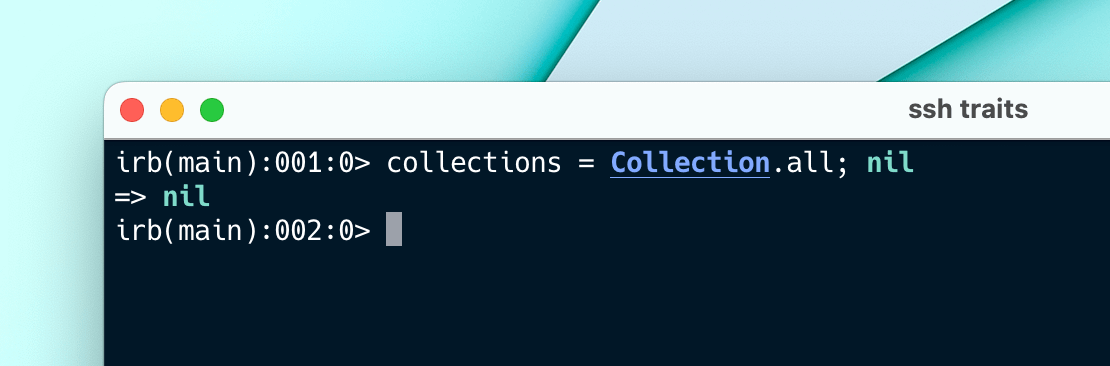
🚚 Use Sidekiq's push_bulk
Pushing lots of small jobs to Sidekiq is great. But pushing stuff to Redis does require a full network round-trip.
Use bulk queing to push many jobs to Sidekiq all at once.
github.com/mperham/sidekiq/wiki/Bulk-Queueing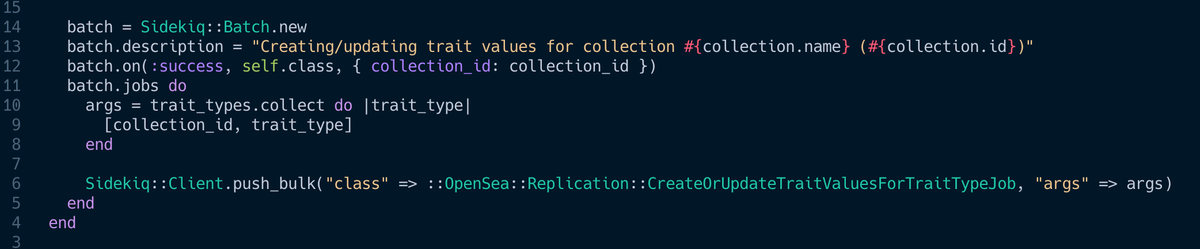
👉 Use Sidekiq batches
Batches let you run a bunch of jobs and a callback when the jobs are finished. I often use these callbacks to instantiate the next job to further process the data.
github.com/mperham/sidekiq/wiki/Batches
They also provide a nice overview of the progress.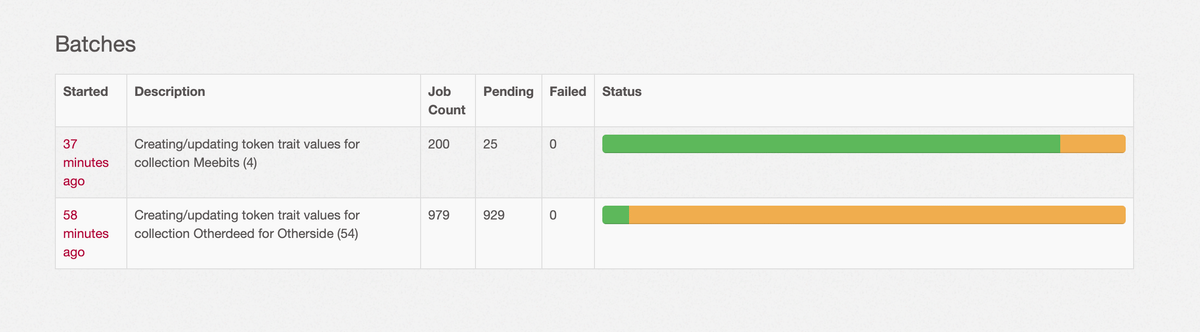
⚡️ Use .find_each over .each
Post.all.each loads all posts into memory before it starts iterating. To reduce memory usage you'll want to use .find_each instead which loads the records in smaller batches.
That wraps it up for now!
I'll be looking into using Redis a bit more as well. As it's obviously a lot faster than Postgres in many scenarios.
Please give it a RT if it was helpful and post your own tips below. Thanks!

Marc Köhlbrugge
@marckohlbrugge
Follow along as I build https://traits.xyz https://wip.co https://startup.jobs https://betalist.com https://buildinpublic.com https://pay.game and more