
Beginner-friendly intro to Classification trees 🌲 🧵
The decision tree is a popular Supervised learning algorithm that can handle classification and regression problems.
1) Classification tree: Classify things into categories
2) Regression tree: Predict numeric values
Now we will focus on the first.
Elements of a three:
- Root node: The first decision point. The statement at the top.
- Internal nodes: The intermediate steps.
- Leaf nodes: The end points of the tree. Hold the prediction of the model.
- Arrows: Represents the data flow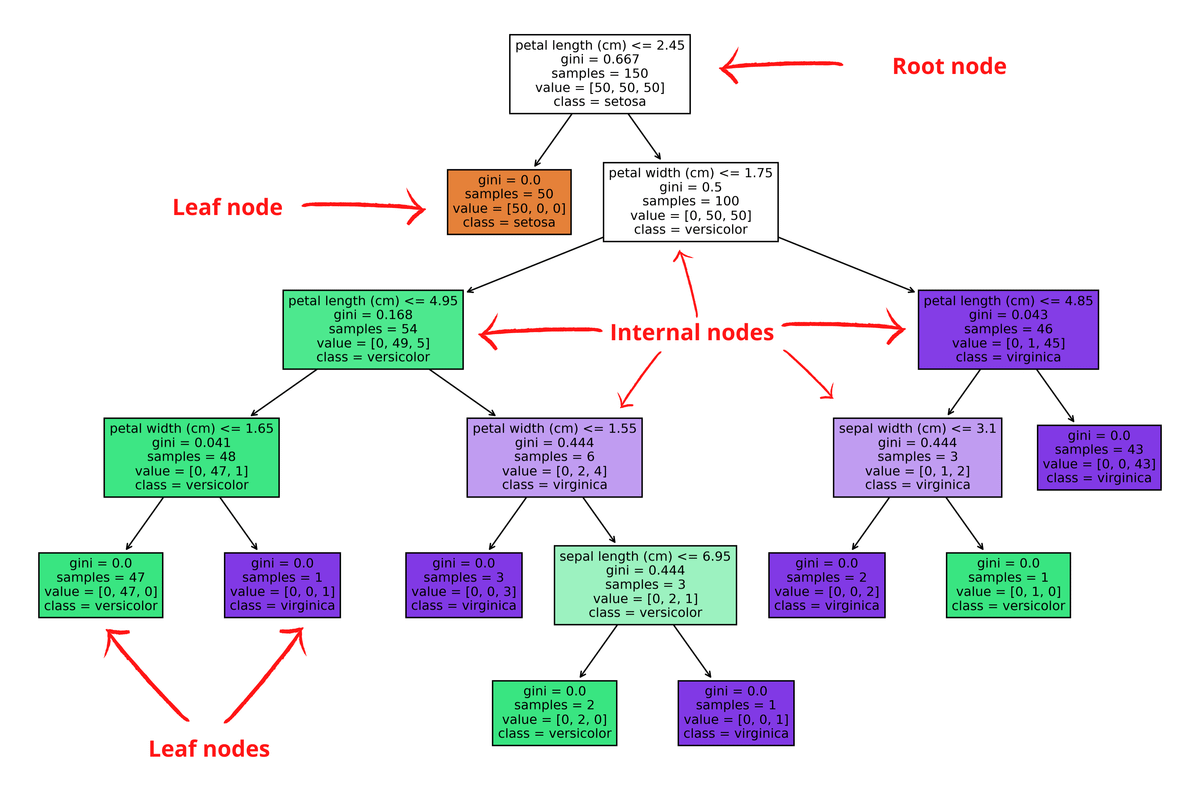
- Root nodes have only outgoing data (arrows out)
- Internal nodes have both incoming and outgoing data (arrows in & arrows out)
- Leaf nodes have only incoming data (arrows in) and they present the final classes.
A general decision tree makes decisions based on whether a statement is true or false.
True - We go to the left
False - we go to the right
Now analyze our tree step by step.
In the example, I used the scikit-learn built-in Iris dataset.
It contains 150 plants. Our categories are Setosa, Versicolor, and Virginica. we have 50 data entries in each category.
1. Let's zoom into the root node:
The first decision point: Is petal length smaller or equal to 2.45?
Since all the Setotas have smaller petal lengths than 2.45 and there is no other plant on the True side, we have our first Leaf node!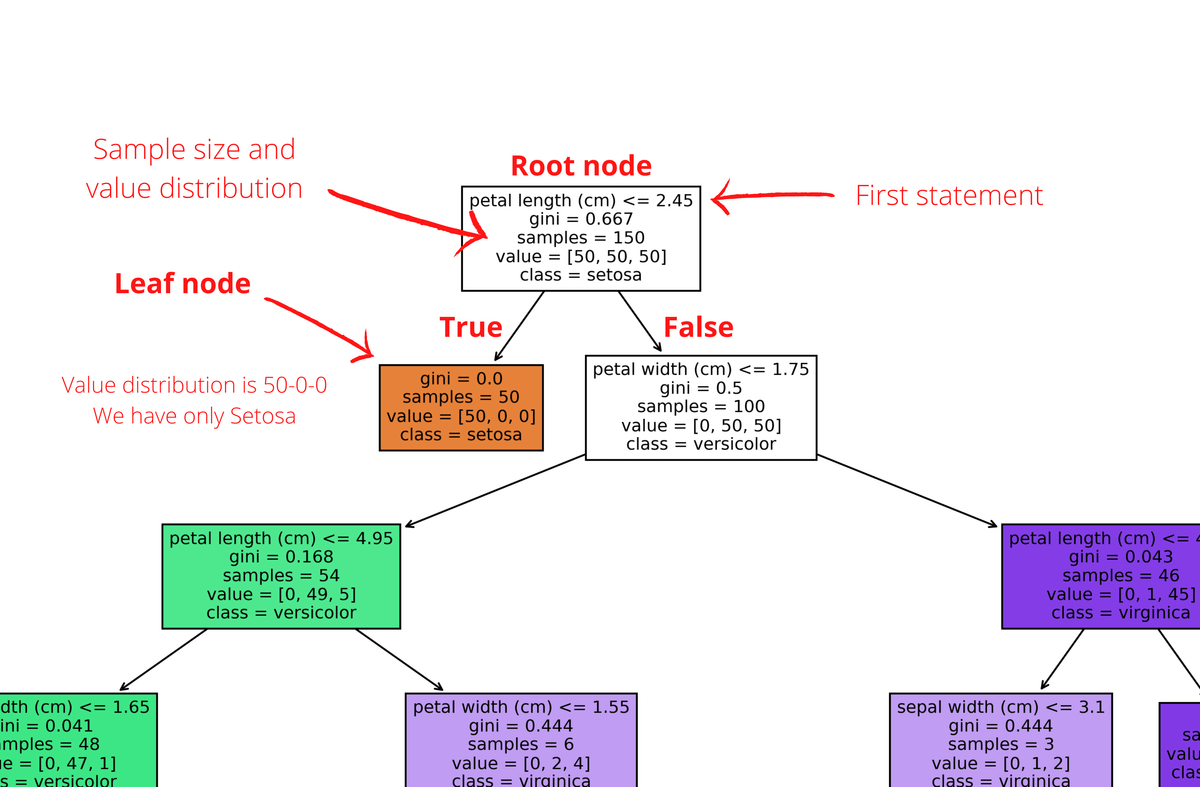
On the false side, we have the remaining 100 values, so we add another statement as an internal node.
We follow this process until we classify all our data and reach pure leaves.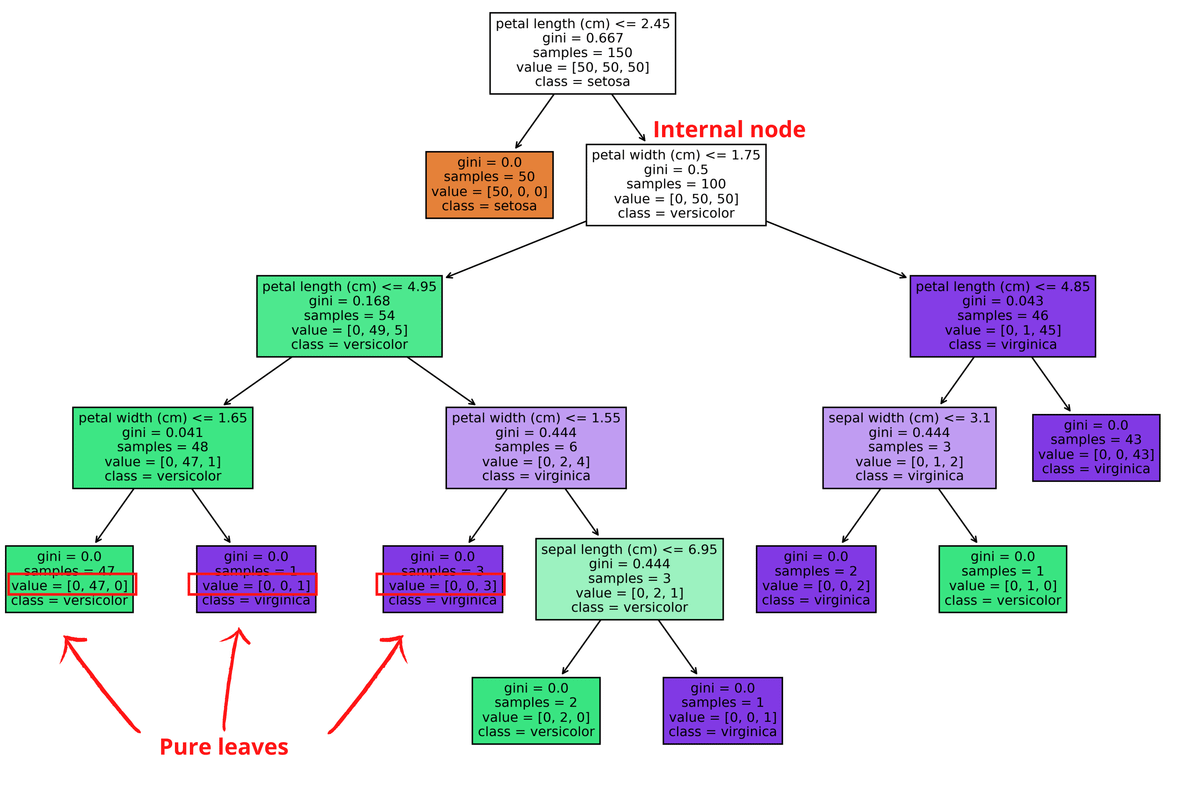
In this example, we have only pure leaves, but in some instances, we will encounter impure leaves at the end.
Impure leaves are containing a mixture of categories.
To measure impurity we have Gini impurity and Entropy
1)
Gini impurity is calculated by subtracting the sum of the squared probabilities of each class from one.
Gini impurity = 0: All the data belongs to the same class
Gini impurity = 0.5: Half of the data belong to one class and the half belong to the other class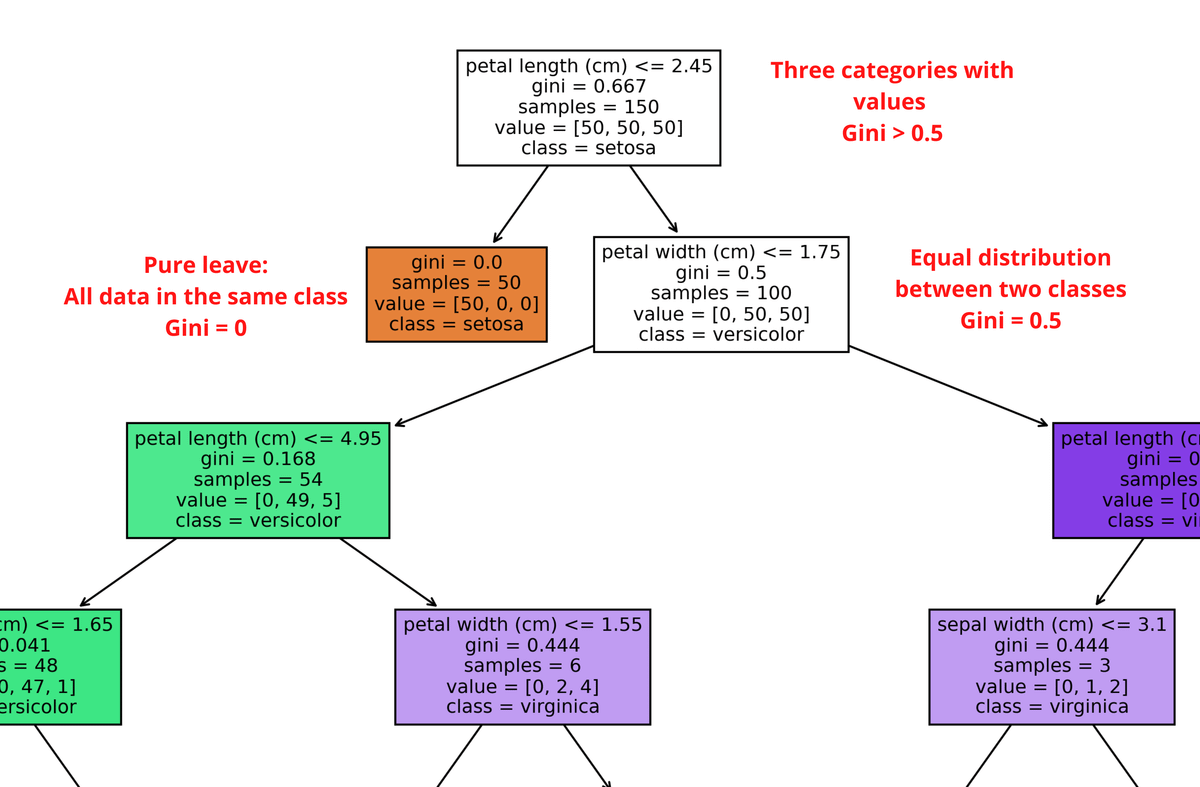
If we see a Gini impurity greater than 0.5 that means that we have more than two categories and there is data in each of those categories.
The maximum value for Gini is 1.
2)
Entropy is calculated by the sum of the probability of each event multiplied by the log of the probability of each event.
Entropy = 0: All the data belongs to the same class
Entropy = 1: Half of the data belong to one class and the half belong to the other class
Maximum values for Entropy:
• 2 Classes: Max entropy is 1
• 4 Classes: Max entropy is 2
• 8 Classes: Max entropy is 3
• 16 Classes: Max entropy is 4
Here is the same example using the entropy method: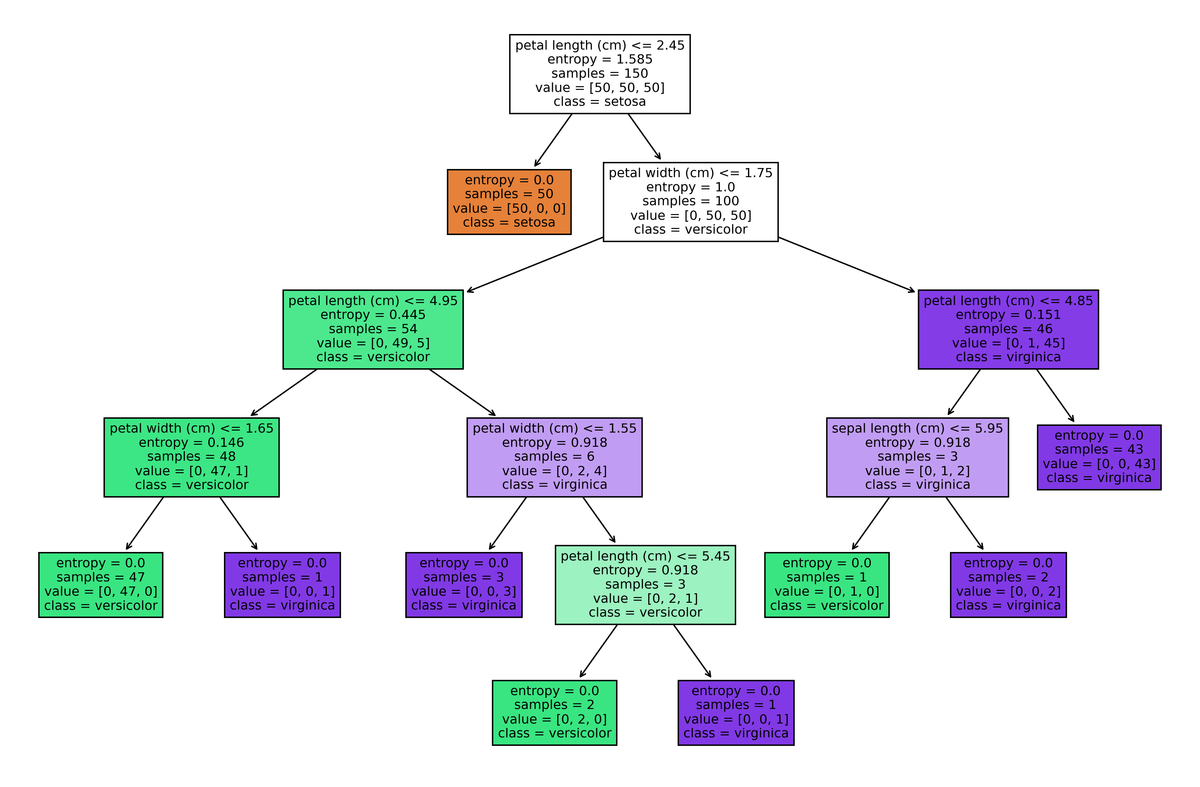
The goal of a decision tree problem is to reduce impurity while building the tree.
So lower Gini or Entropy means better results.
At each stage, the tree algorithm should choose the split that minimizes the outcome impurity.