Turns out I was wrong. Gemini is 30x cheaper for transcription (same quality) if you prompt right and segment to stay under 128k.
So how good is it? It's crazy for clean audio (source+code in 🧵)
AssemblyAI: 92.06% ($0.21)
Flash-002: 92.68% ($0.00679) 🤯
Let me say more 👇
For long clean audio we're using @VaatiVidya's awesome video on SoTET (youtube.com/watch?v=ldTQoUxROzY).
Full results:
AssemblyAI: 92.06% ($0.21)
🤯 Gemini Flash 002: 92.68% ($0.00679)
Flash 002 (with better prompt): 92.84%
Whisper Turbo: 81.05%
Actually there's one more model -
and this is the really crazy one.
Gemini-flash-8b gets 90.21% accuracy for only $0.0033
That's 60x cheaper 😱
With logprobs available (h/t @OfficialLoganK and the team) the next experiment is to see if we can use those to resample certain bits.
But how does dirty audio fare?
This is where things change - likely because of pre-processing pipelines for this kind of thing.
Let's take this audio: github.com/SouthBridgeAI/llm-transcription-study/blob/master/comparisons/voilatest/V.mp3
I can barely make sense of it - apparently neither can Gemini!
Points if you've figured out the passage even from this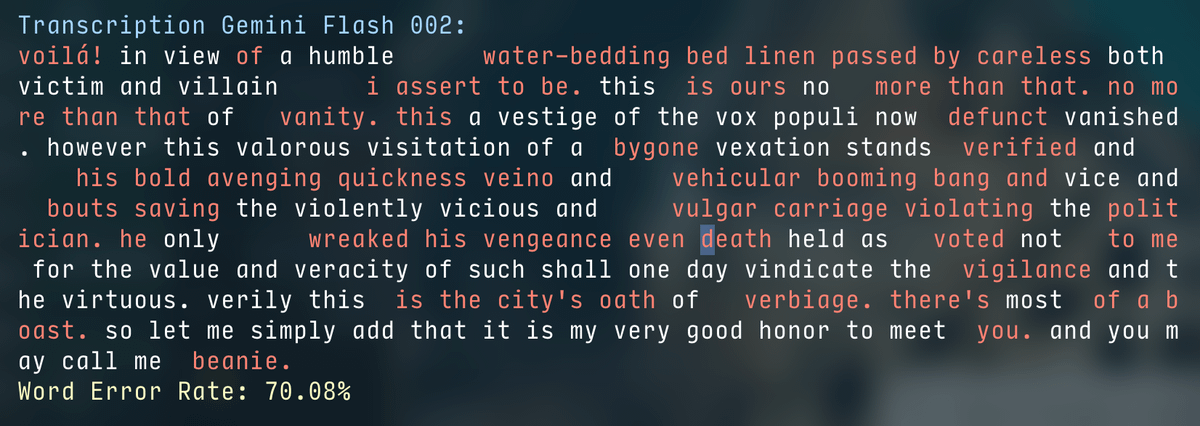
Remove the noise and it gets much better
Much better than Whisper, but not better than Whisper with noise removal
Still not as good as AssemblyAI!
For now the prompts+results are at github.com/SouthBridgeAI/llm-transcription-study.
The real power in using LLMs is that they can do a lot more processing after - including speaker separation, speaker identification from video, and so much more.
Next is diarization, results later

Hrishi
@hrishioa
In SF in March - Building artificially intelligent bridges at Southbridge, prev-CTO Greywing (YC W21). Chop wood carry water.