What is LLM Self-Consistency?
Improving reasoning by following multiple paths
I swear everything we're doing now is just thinking hard about how humans think and writing algorithms
Paper breakdown with useful takeaways🧵👇💭
arxiv.org/abs/2203.11171
I talked about Boosted Ensembles before, and they use Self-Consistency as the method to find 'Hard' problems within a dataset
Even without it, Self-Consistency is an amazing way to improve reasoned results, compeltely unsupervised
twitter.com/hrishioa/status/1646449264711843840?s=20
When I was in high school I was bad at practiced math but good at the concepts
If I did 10 problems I would just be wrong on 4 - bad reliability scores, something I share with GPT
My solution was to do the same problem thrice and see if I got the same result
It's basically what Self-Consistency applies
What I had to do was to come back to the problem another day so I'd forgotten how I did it the first time
With LLMs there's temperature - you can randomize output probabilities with a single parameter
Here's an example with a simple logic problem that GPT-4 gets wrong thrice, but with different patterns of reasoning. One method is pictorial, the others are differently verbal



We have two ways of adjusting the answers and the reasoning (without human intervention):
Probability - how likely did the model think this output was
Normalized prob - normalize the conditional probability over the output length
When we have a set of scores (or how good the answers were), we can
average, sum or pick the most consistent (most common) answer's score
These heroes show that the majority vote is the best performer, close is the unweighted sum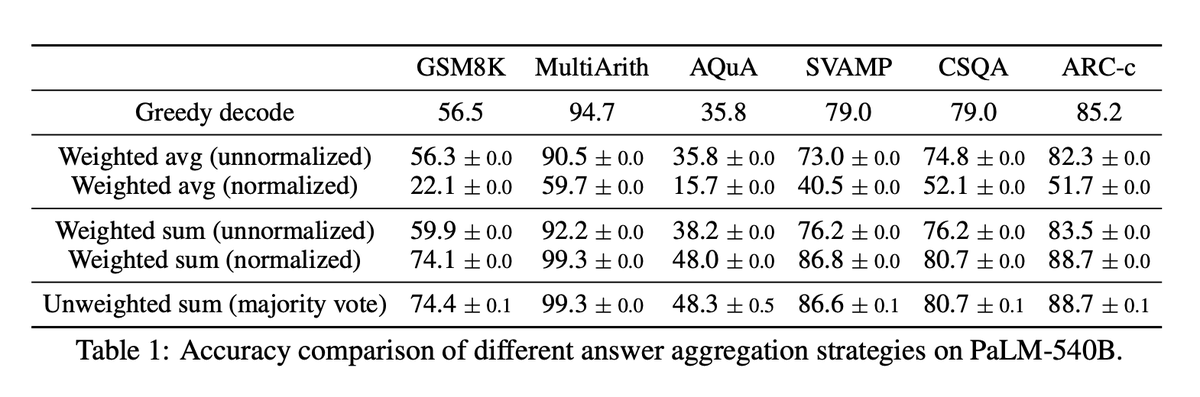
What can we learn that's useful?
👉 temperature is your friend (this is something I need to internalize) - high temperature for reasoning with multiple passes can tell you a lot about a problem
Have a good prompt? Turn up the temperature and test reliability
👉 Add self-consistency as a measure of protection against imperfect prompts (or as a checker to your main prompt)
What I'm interested to test later is how results improve if the model is presented with different reasonings and asked to pick one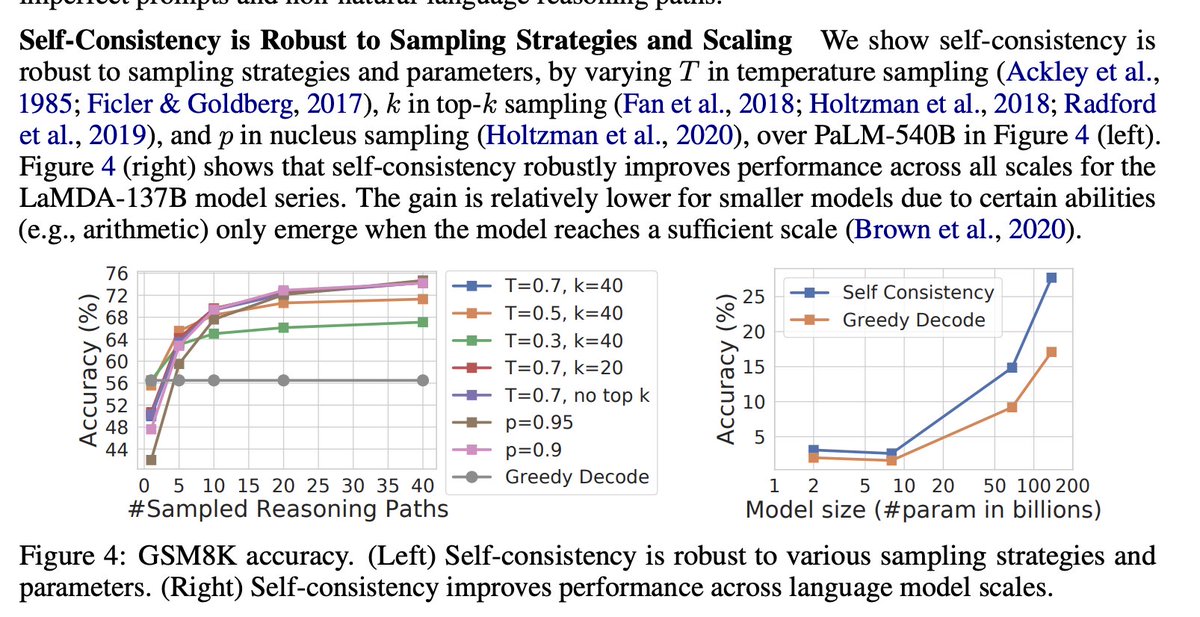

Hrishi Olickel
@hrishioa
Building artificially intelligent bridges at Southbridge, prev-CTO Greywing (YC W21). Chop wood carry water.