Among all the cool things at NeurIPS I wanted to call out this gem: CoCoNUT (not sure who's in charge of naming at @AIatMeta
Direct latent space reasoning by connecting the last and first layers, without collapsing the distributions into a single token.
Interesting: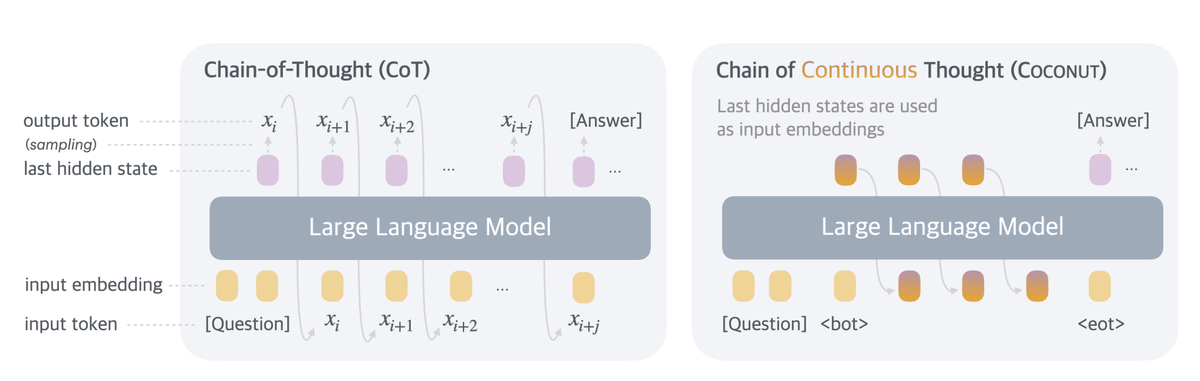
The process seems simple enough - get the model to insert <bot> and <eot> tokens, and in between those use the output of the last layer as input to the first.
Instead of condensing the last layer to a token and using that token as input.
Models are trained with increasing numbers of 'latent thoughts', while masking the loss on the latent thought tokens.
They have the models launch straight into thinking, while (for now) artificially capping the number of thoughts.
What captivated me is nonverbal thinking. As someone with a very textual (and hyperactive) internal monologue, it was easy to presume that longer CoT tokens are the way to go.
But maybe our internal latent spaces think without language.
Also released is a new dataset (ProsQA) with additional tree-like reasoning paths embedded in questions.
Bigger than ProntoQA both in number of samples and size
Unsurprisingly, reasoning performance goes up with latent thinking tokens, in a very token-efficient manner.
What's interesting is how the distribution changes with the number of thinking tokens. The categorization is important here, I'll leave it to you to find it in the paper!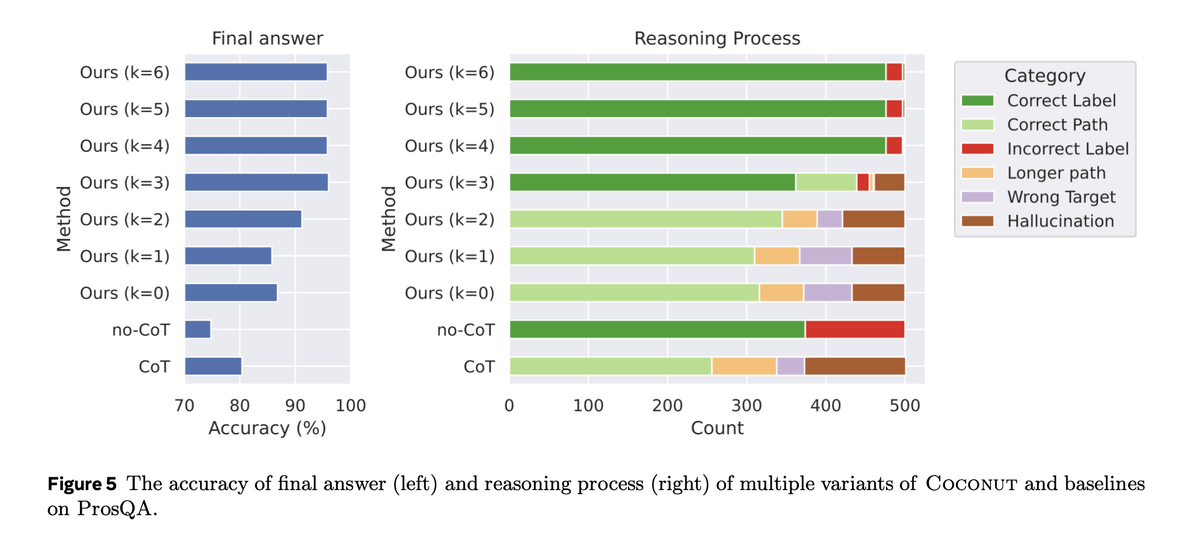
What's also cool is you can condense the latent reasoning "tokens" into proper tokens if you want some inspectability.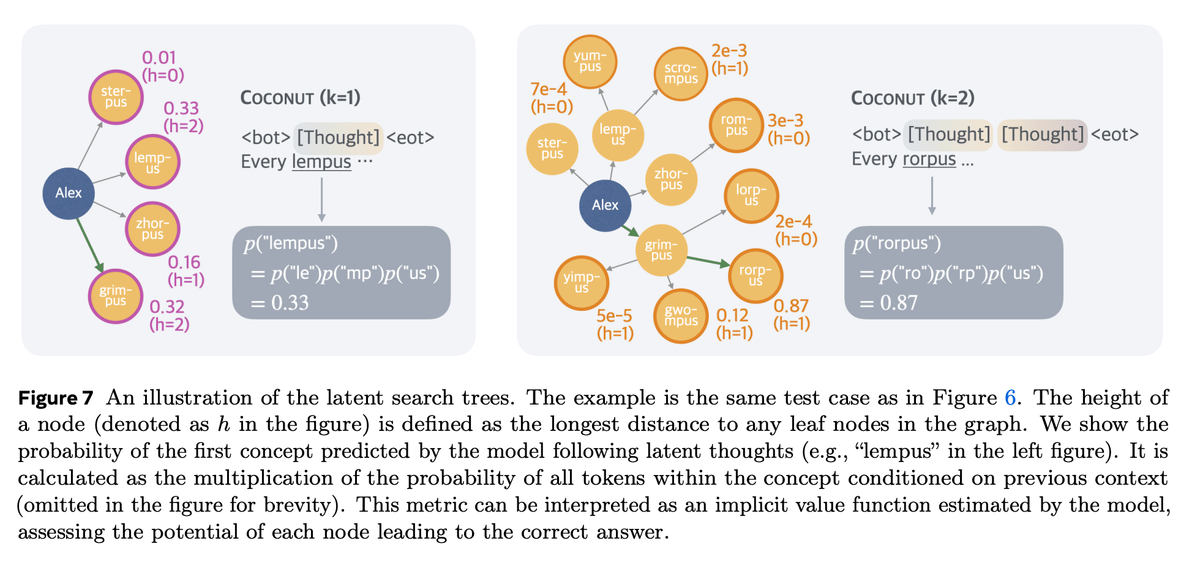
The primary hypothesis is that allowing for this kind of connection lets models explore multiple paths in parallel (since all token probs are present instead of just one real token), and there's some evidence.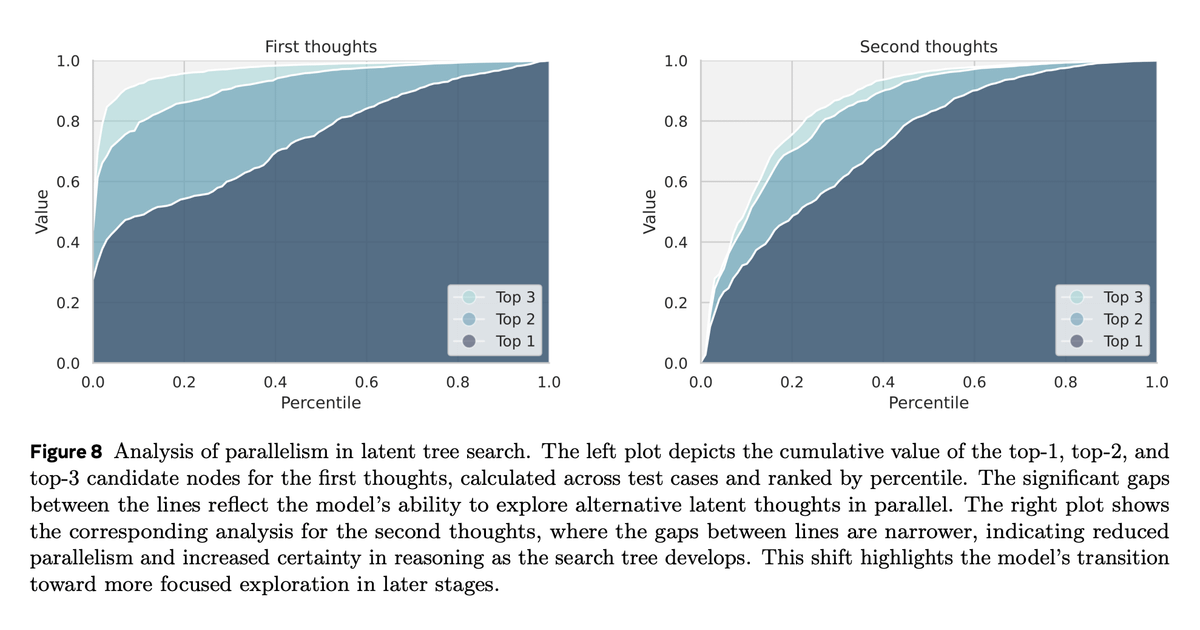
What's more interesting would be looping connections between other layers and ways to activate those.
Increasing inference time thinking has been one of the really interesting avenues in improving model performance lately - QwQ has been one of the best models of the year.
Thank you @Ber18791531, @tesatory, Andy Su, @xl_nlp, @ZhitingHu, @jaseweston, and @tydsh for the paper!
This is a great thread that goes into more detail and more links - found it too late 😅
x.com/Ber18791531/status/1866561188664087017

Hrishi
@hrishioa
In SF in March - Building artificially intelligent bridges at Southbridge, prev-CTO Greywing (YC W21). Chop wood carry water.