If you are a beginner this is the most common SQL interview question
"How to find duplicate data ?"
Here are 5 different ways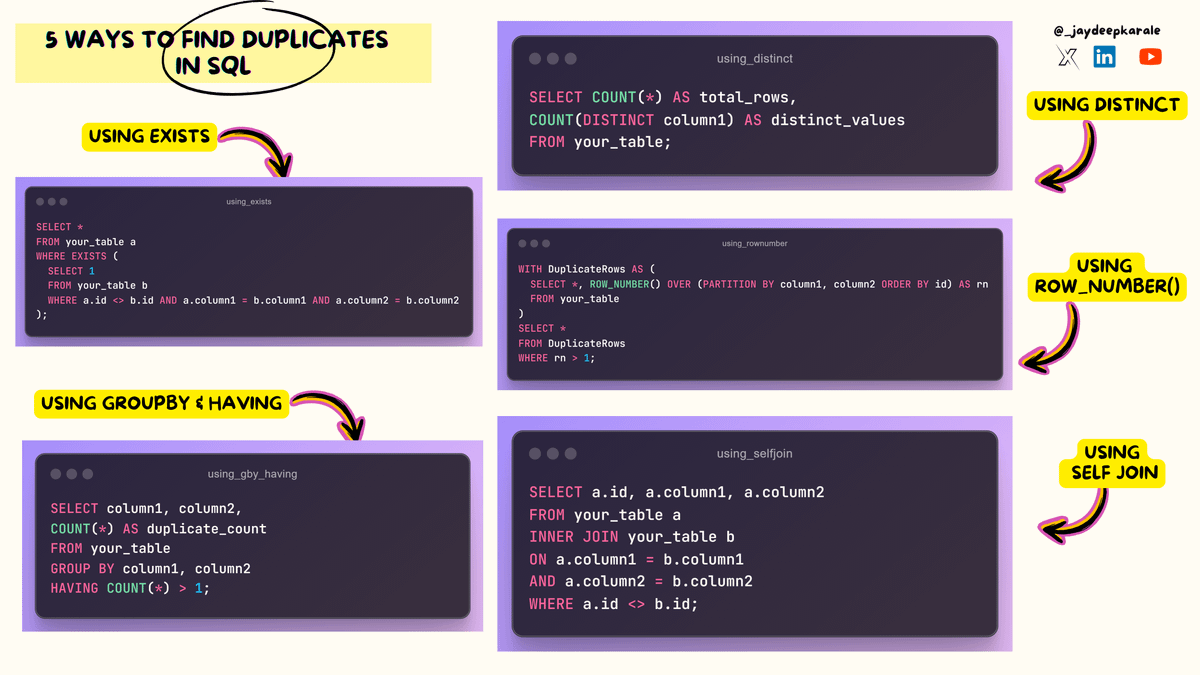
{ Using GROUP BY & HAVING Clause }
• This method is effective for finding duplicate records based on specific columns
• Group the data by the columns you want to check for duplicates
• Use the HAVING clause to filter groups with more than one record
{ Using Self Join }
• A self-join can be used to compare rows within the same table
• Join the table with itself based on the columns you want to check for duplicates
• Filter the results to find rows where the primary key values differ but the other columns are identical
{ Using ROW_NUMBRE() }
• This method assigns a sequential number to each row within a partition
• Create a partitioned result set using ROW_NUMBER()
• Filter rows with a ROW_NUMBER greater than 1 to identify duplicates
{ Using EXISTS Clause }
• The EXISTS clause can be used to check for duplicate records based on certain conditions
• Create a subquery to find potential duplicate records
• Use the EXISTS clause to check if a matching record exists in the subquery
{ Using DISTINCT }
• While not directly for finding duplicates, DISTINCT can be used to identify unique values in a column
• Count the total number of rows
• Count the number of distinct values in the target column
• If the counts differ, duplicates exist

Jaydeep
@_jaydeepkarale
Follow Me If You Like 🐍 Python 🤖 Machine Learning/AI ⚙️ Software Engineering 📊 Data Visualization 📩 DM For Collab youtube.com/@jaydeepkarale