
הסיפור המעניין הזה על האדם שניצח את הAI בGo הוא הזדמנות טובה לדבר על הבעייתיות בגישה הסטנדרטית של תורת המשחקים לניתוח משחקים רב שלביים. #שרשור_תורת_המשחקים בפורמט של תהיות בקול רם:
twitter.com/talitshe/status/1627429196820631552?t=ZBHt1N7mxlKHQXBGFL168w&s=19
הדרך הסטנדרטית לנתח משחקים רב שלביים, כמו Go או שחמט, היא באמצעות המושג של שיווי משקל פרפקטי, שהוא פרופיל אסטרטגיות המהווה ש"מ נאש בכל תת משחק. מה שזה בעצם אומר זה שכל שחקן משחק אופטימלית לא רק ביחס למצב ההתחלתי של המשחק, אלא גם ביחס לכל מצב אפשרי שהוא עשוי להיקלע אליו בדרך.
twitter.com/OmerMadmon/status/1572988019283476481
הדרך הסטנדרטית למצוא ש"מ פרפקטי במשחקים רב שלביים סופיים היא ע"י ביצוע אינדוקציה לאחור: פתירת המשחק "מהסוף להתחלה". זהו גם הרעיון העומד בבסיסה של תכנת המחשב Deep Blue שניצחה את קספרוב בשחמט ב1997.
נו, אז מה הבעיה?
twitter.com/OmerMadmon/status/1609508354820575232
כדי להבין את הבעיה נסתכל על הדוגמא של "משחק מרבה הרגליים"[1]: בכל תור אחד משני השחקנים צריך להחליט אם לעצור את המשחק או להעביר את התור לשחקן הבא. בואו נבצע אינדוקציה לאחור: בשלב האחרון שחקן 2 צריך לבחור אם לשחק r ולקבל 3, או לשחק d ולקבל 4, והוא כמובן יבחר בd.>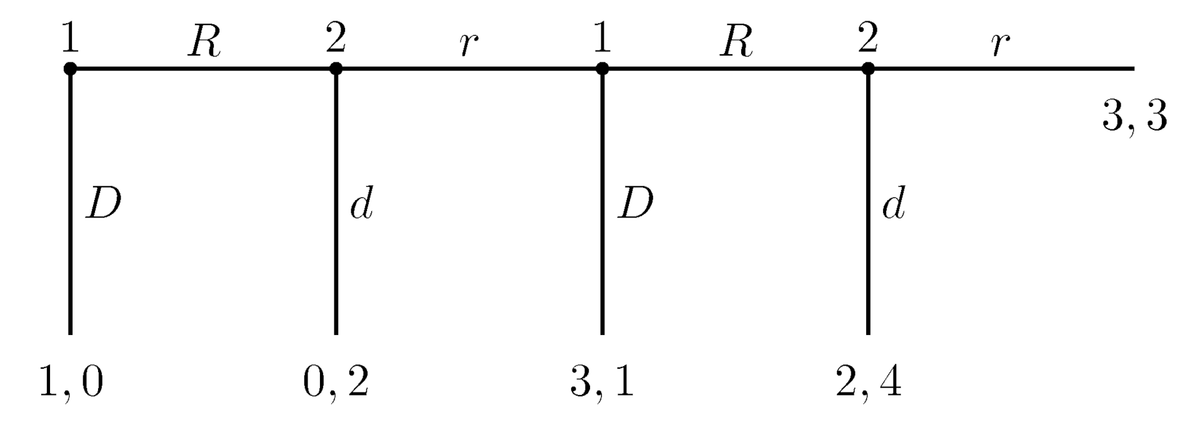
שחקן 1 יודע זאת, ולכן בשלב הלפני-אחרון הוא יעדיף לשחק D ולהרוויח 3 (ולא לשחק R ולקבל את ה2 ששחקן 2 ישאיר עבורו). כך הלאה נקפל את המשחק עד שנקבל את התוצאה שבה שחקן 1 כבר בשלב הראשון בוחר לסיים את המשחק, כלומר לשחק D בקודקוד ההחלטה הראשון - מה שיתן לשחקן 1 תועלת 1 ולשחקן 2 תועלת 0.
הבעיה עם הניתוח הזה היא שהוא מתעלם לחלוטין מהעובדה ששחקן 2, למשל, בקודקוד ההחלטה השני במשחק, מניח ששחקן 1 רציונלי. אבל אם הגיע תורו של שחקן 2 לשחק, זה אומר שמלכתחילה שחקן 1 לא היה רציונלי (או ששחקן 1 לא הניח ששחקן 2 רציונלי בעצמו)! משהו בהנחות היסוד לא מסתדר.>
אם שחקן 2 קיבל את הזכות לשחק בשלב השני, הוא אמור היה גם לקבל סיגנל לגבי מידת הרציונליות של שחקן 1 - או שהוא לא רציונלי, או שהוא לא מאמין ששחקן 2 יהיה רציונלי. אז איך כל זה קשור למשחקים בין אנשים למכונות? האמת, זאת שאלה ממש טובה.>
גישות קלאסיות כמו Deep Blue אינן עושות שימוש בלמידה מדאטה, אלא משערכות את אסטרטגיית שיווי המשקל הפרפקטי של המחשב, ולכן יעבדו מצוין מול יריב רציונלי כמו קספרוב. עם זאת, הגישה הזו לא בהכרח תגיב אופטימלית ליריב שאינו רציונלי, שהרי בניית האסטרטגיה נעשית תחת הנחת רציונליות של היריב.
ומה לגבי אלגוריתמי למידה? אז כאן קשה יותר להגיד, כי אנחנו לא ממש יודעים על איזה דוגמאות המודל אומן. סביר להניח שהמודל אומן על הרצות של משחקים בין שחקנים שהם בקירוב רציונליים (לפחות רוב הדוגמאות), ומכאן שהאסטרטגיה שנלמדה כנראה מניחה בעקיפין גם היא רציונליות, לפחות ברמה מסוימת.
הפתרון שאני מצליח לחשוב עליו הוא אימון של מודל שלא רק לומד אסטרטגיה עבור עצמו. אלא גם מנסה ללמוד את האסטרטגיה של היריב תוך כדי המשחק, כלומר במובן מסוים לנסות לחזות את המהלך הבא של היריב על סמך המהלכים הקודמים (קצת כמו ג'יפיטפוט שיודע לשמר את ההקשר של השיחה שהוא מנהל בסשן הנוכחי).
האמת שאני לא יודע עד כמה פתרונות מודרניים הולכים בכיוונים האלה, ואם מישהו בפיד מבין בזה יותר ממני אני אשמח לשמוע :)
מקור:
[1] en.wikipedia.org/wiki/Centipede_game