How does a Large Language Model like ChatGPT actually work?
Well, they are both amazingly simple and exceedingly complex at the same time.
Hold on to your butts, this is a deep dive ↓
You can think of a model as calculating the probabilities of an output based on some input.
In language models, this means that given a sequences of words they calculate the probabilities for the next word in the sequence.
Like a fancy autocomplete.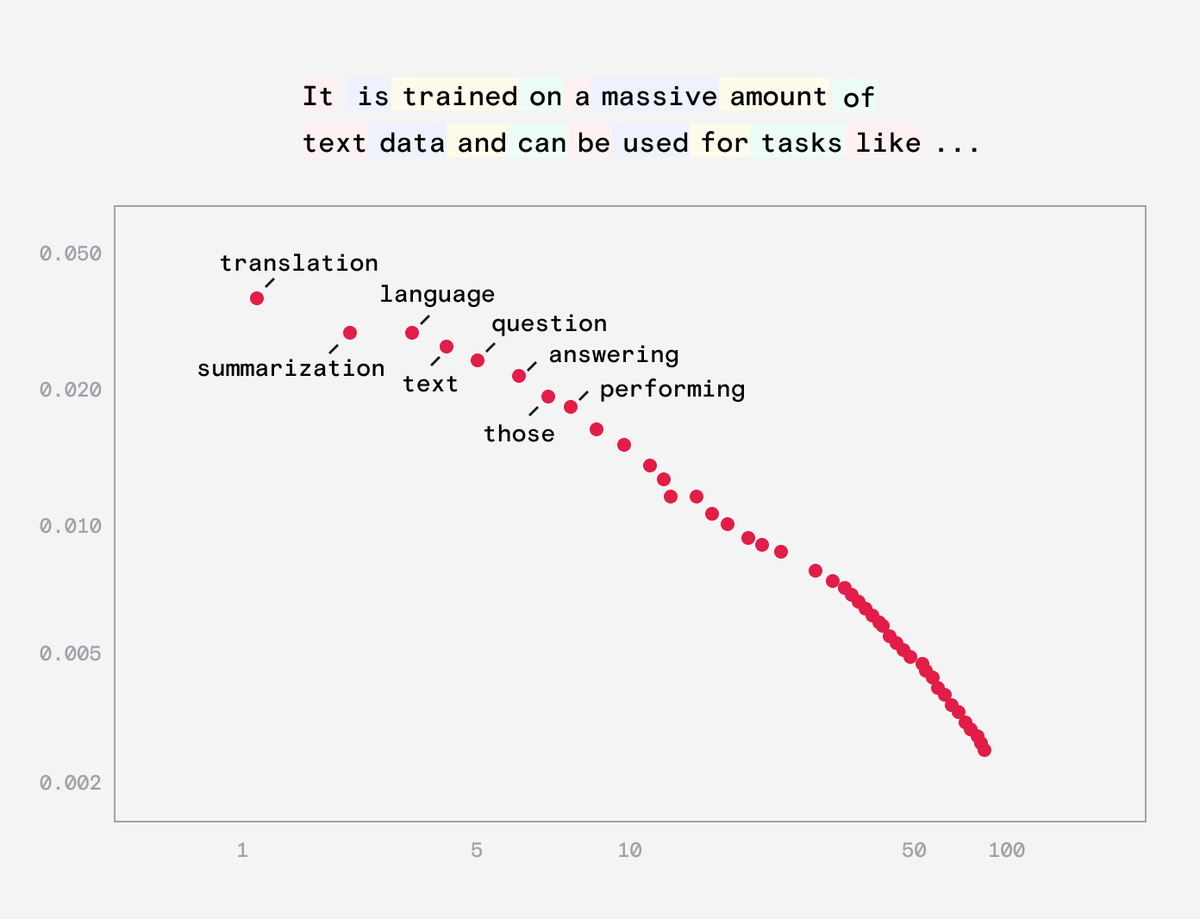
To understand where these probabilities come from, we need to talk about something called a neural network.
This is a network like structure where numbers are fed into one side and probabilities are spat out the other.
They are simpler than you might think.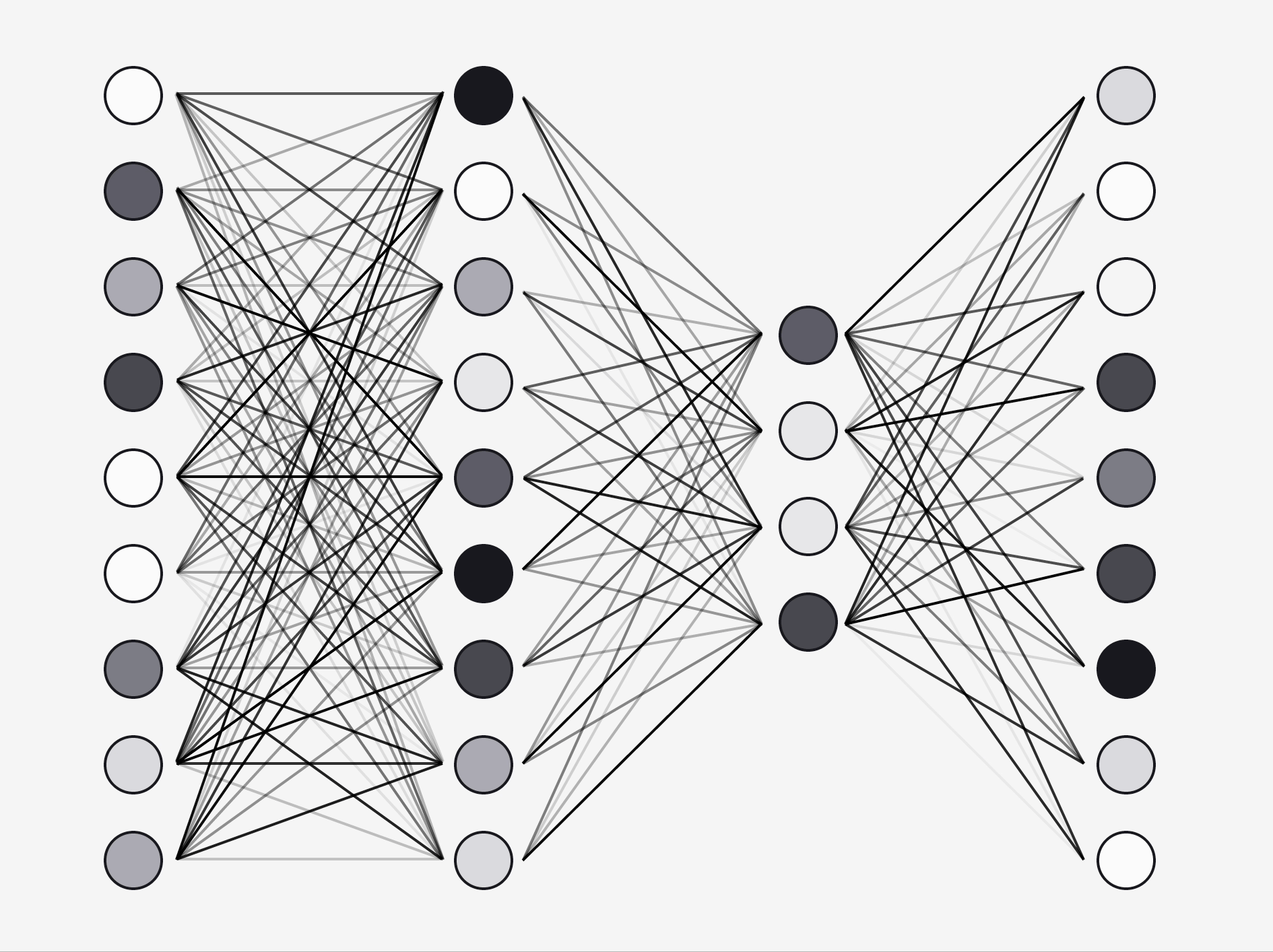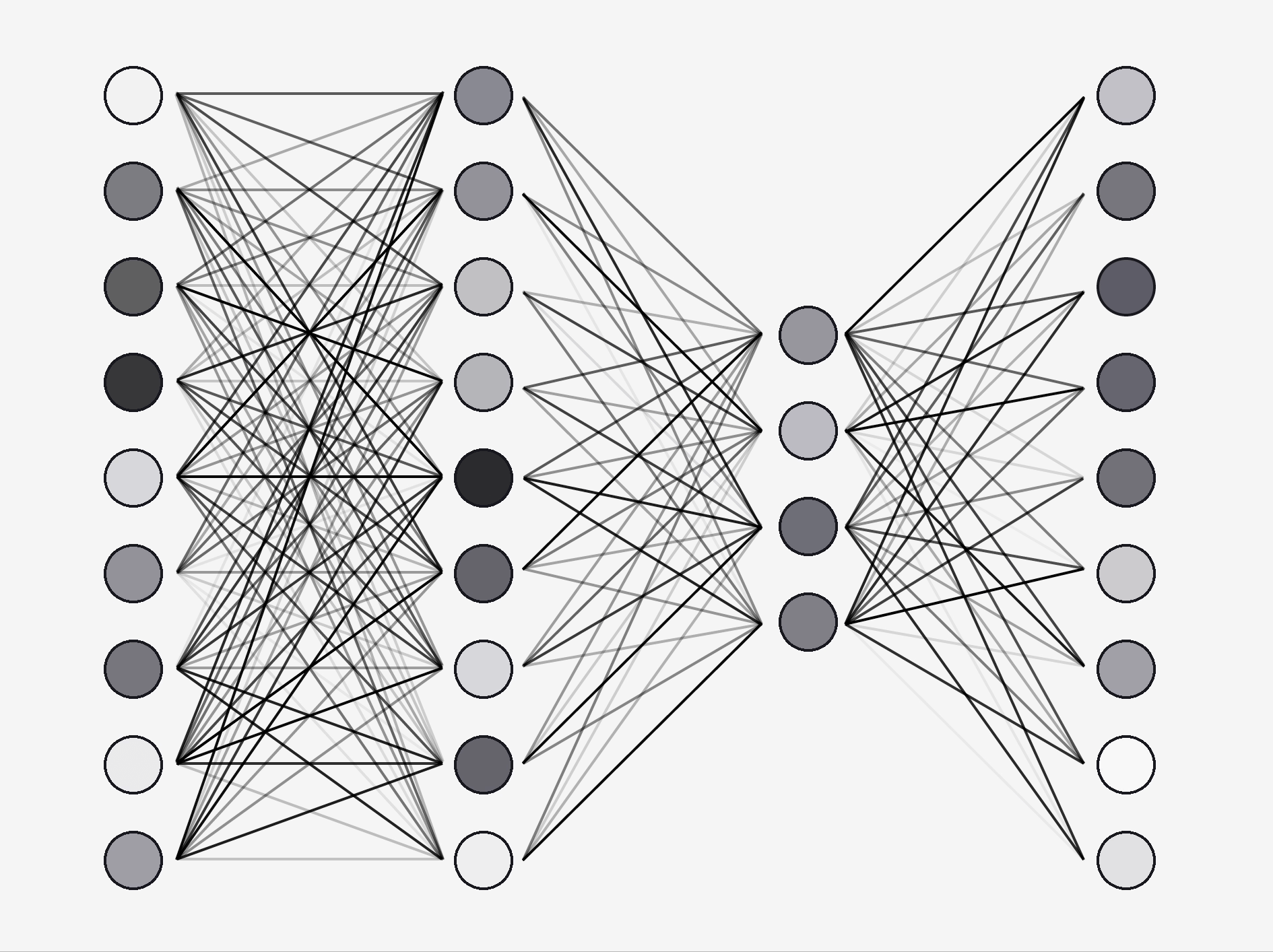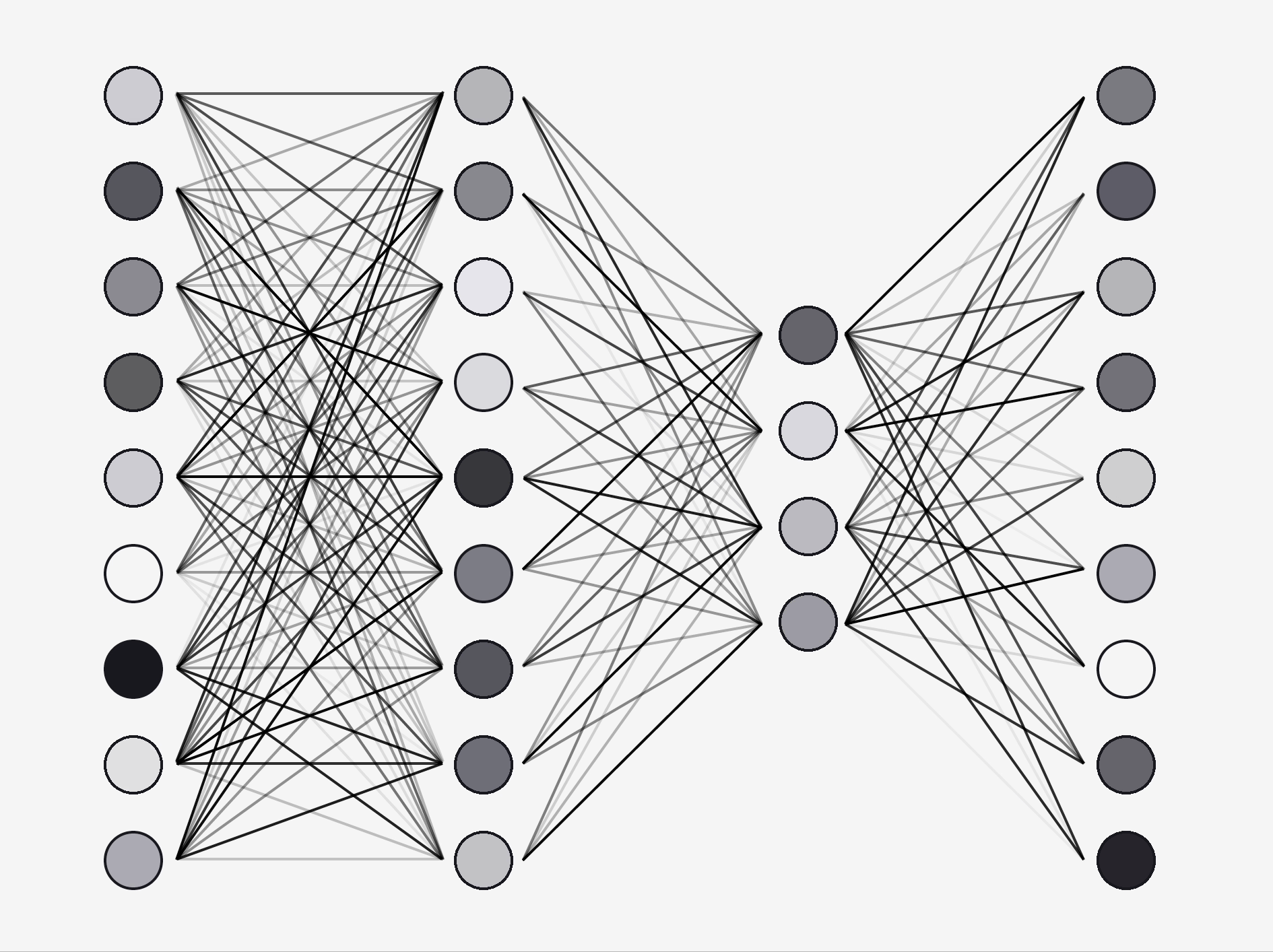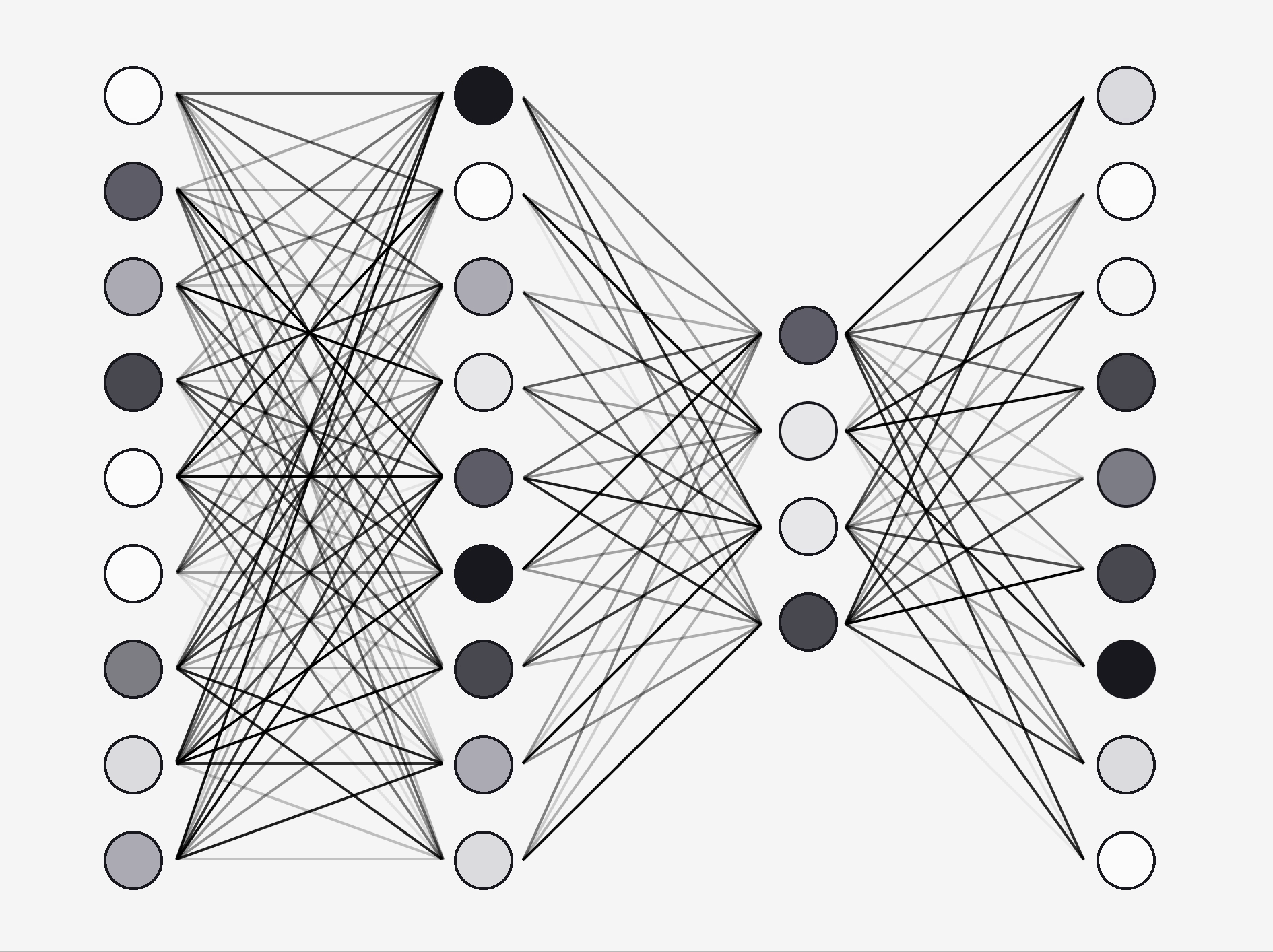
Imagine we wanted to train a computer to solve the simple problem of recognising symbols on a 3x3 pixel display.
We would need a neural net like this:
- an input layer
- two hidden layers
- an output layer
Our input layer consists of 9 nodes called neurons - one for each pixel. Each neuron would hold a number from 1 (white) to -1 (black).
Our output layer consists of 4 neurons, one for each of the possible symbols. Their value will eventually be a probability between 0 and 1.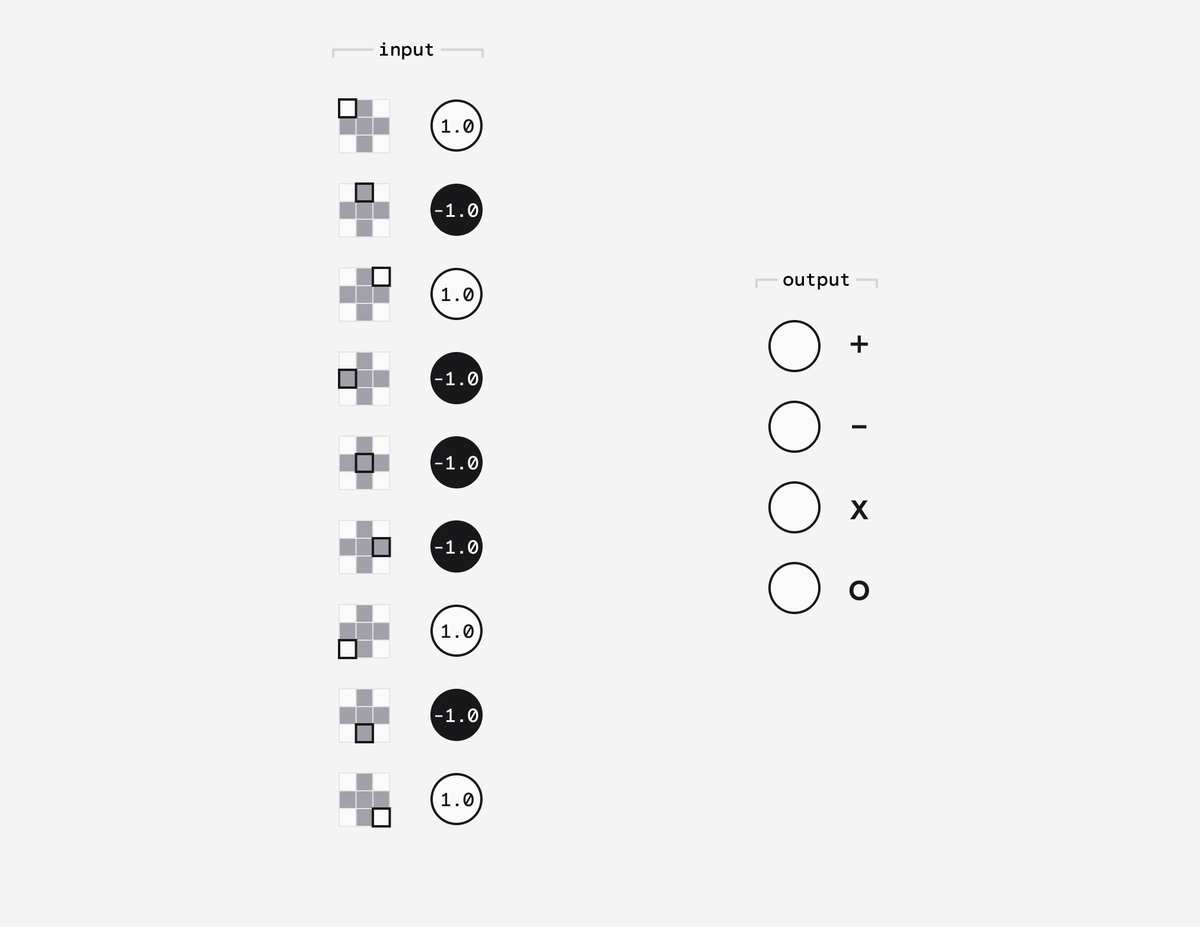
In between these, we have rows of neurons, called "hidden" layers. For our simple use case we only need two.
Each neuron is connected to the neurons in the adjacent layers by a weight, which can have a value between -1 and 1.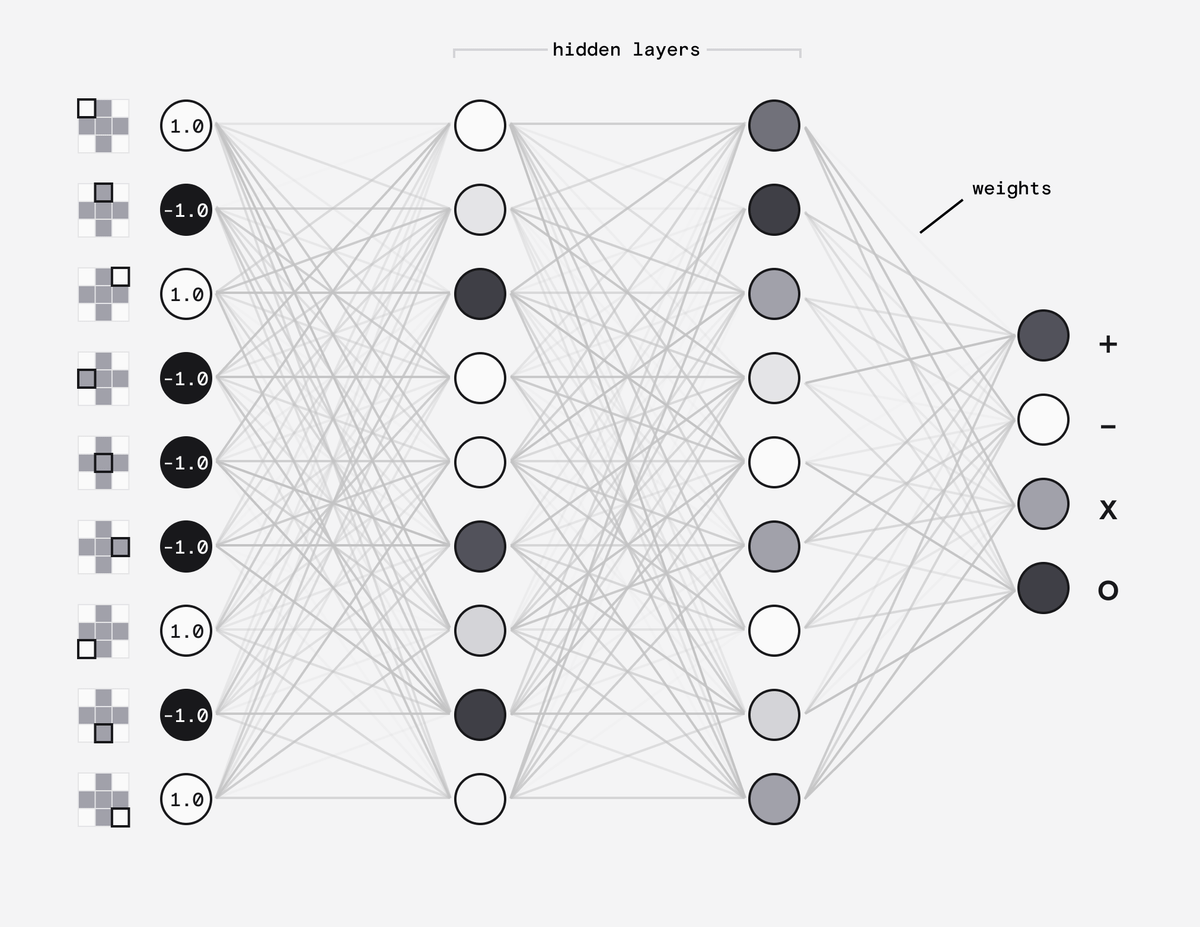
When a value is passed from the input neuron to the next layer its multiplied by the weight.
That neuron then simply adds up all the values it receives, squashes the value between -1 and 1 and passes it to each neuron in the next layer.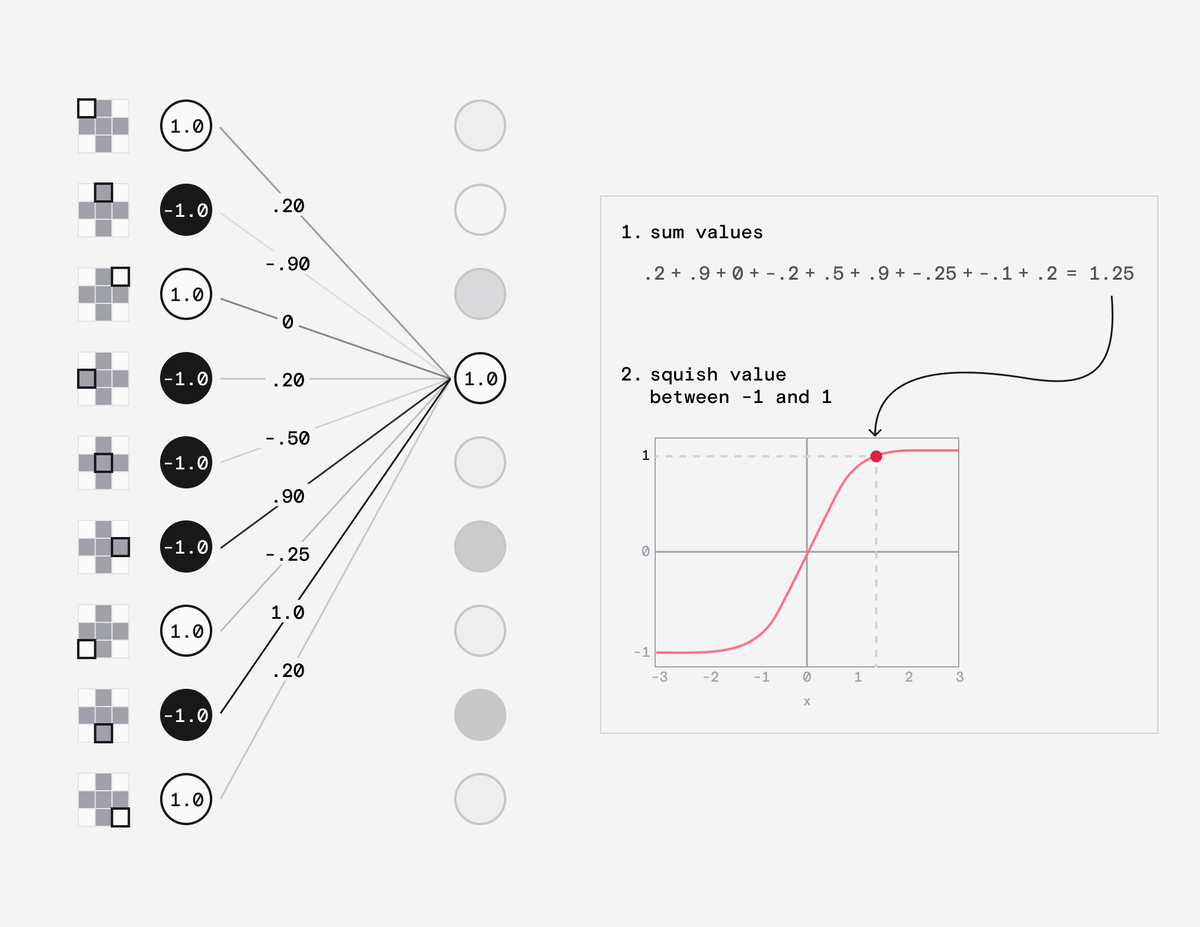
The neuron in the final hidden layer does the same but squashes the value between 0 and 1 and passes that to the output layer.
Each neuron in the output layer then holds a probability and the highest number is the most probable result.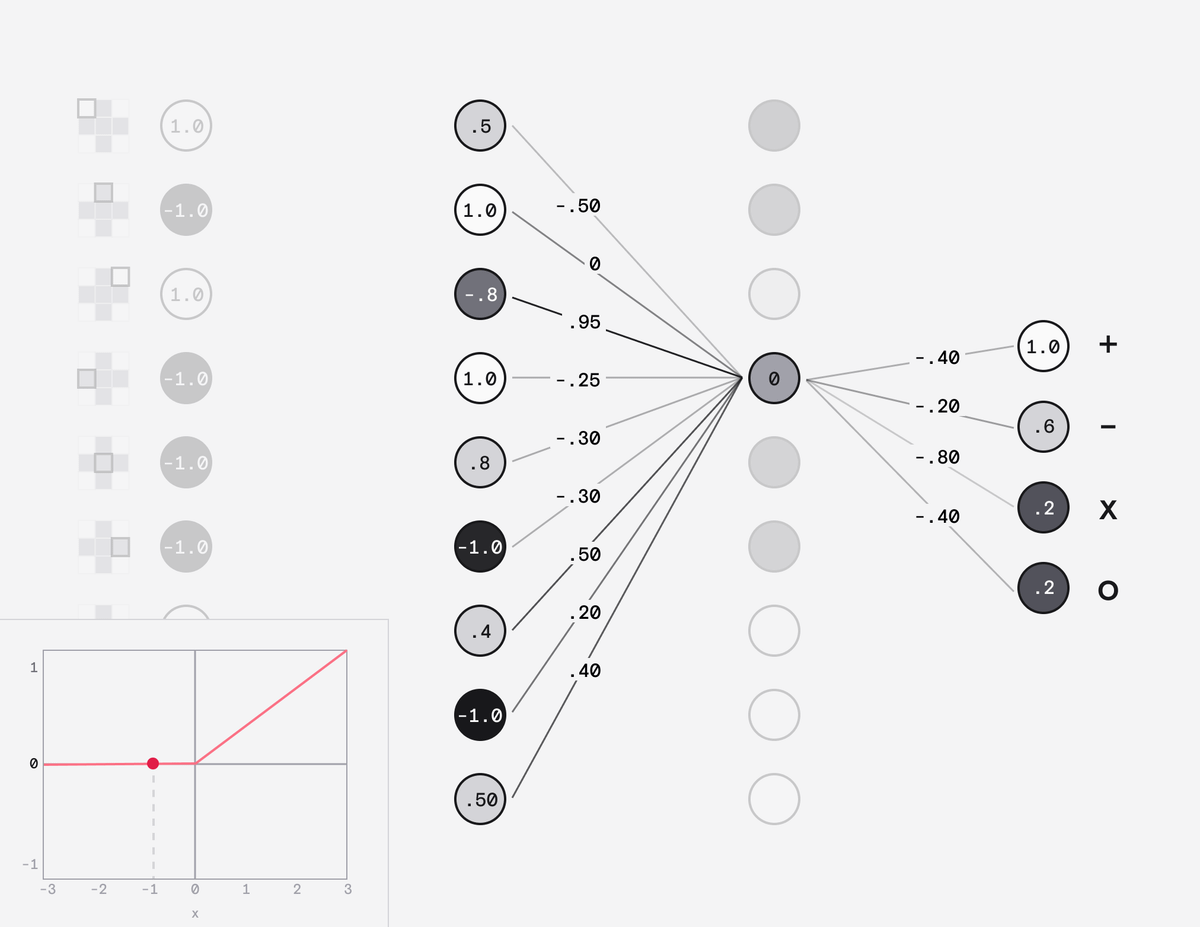
When we train this network, we feed it an image we know the answer to and calculate the difference between the answer and the probability the net calculated.
We then adjust the weights to get closer to the expected result.
But how do we know *how* to adjust the weights?
I won't go into detail, but we use clever mathematical techniques called gradient descent and back propagation to figure out what value for each weight will give us the lowest error.
We keep repeating this process until we are satisfied with the model's accuracy.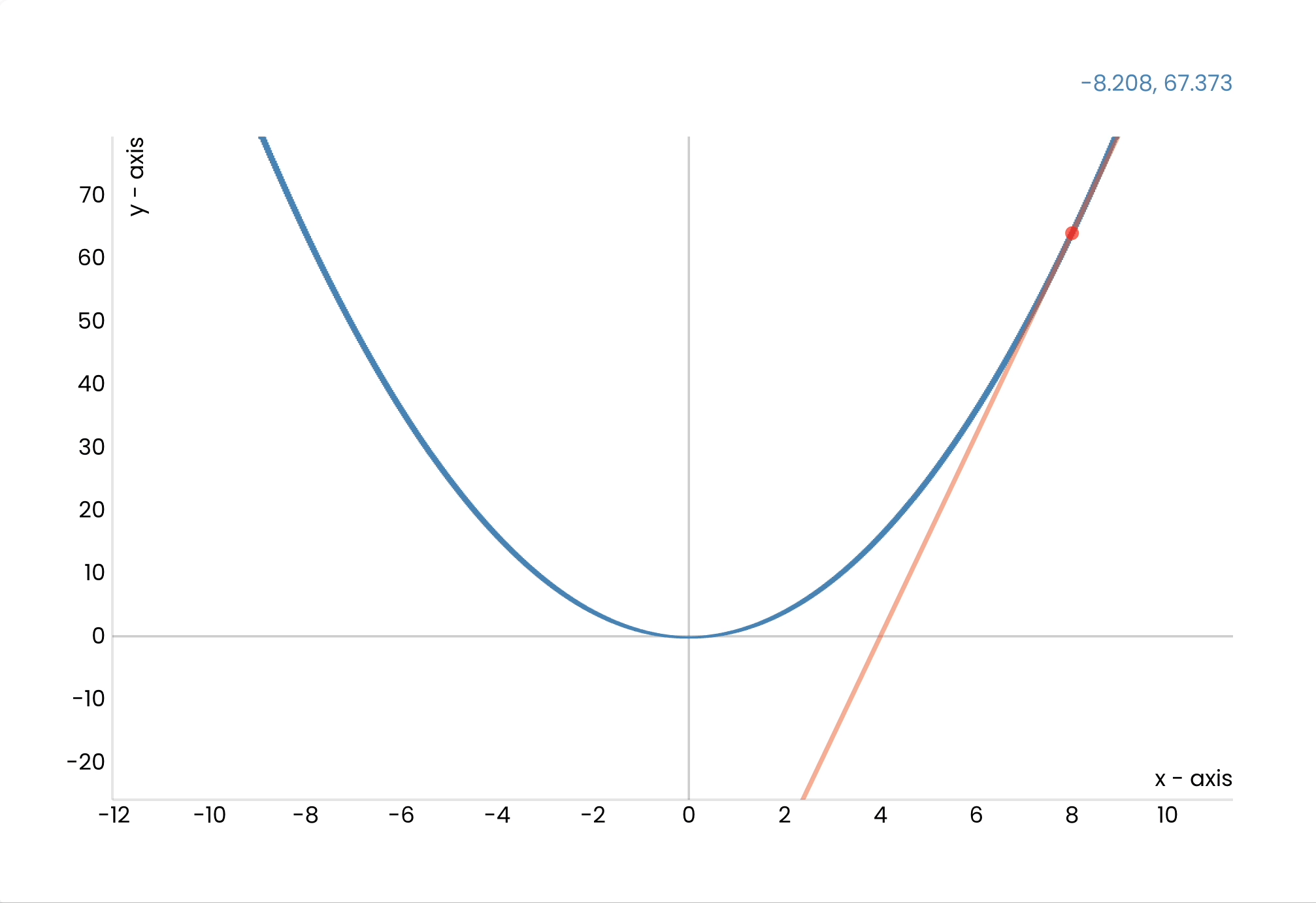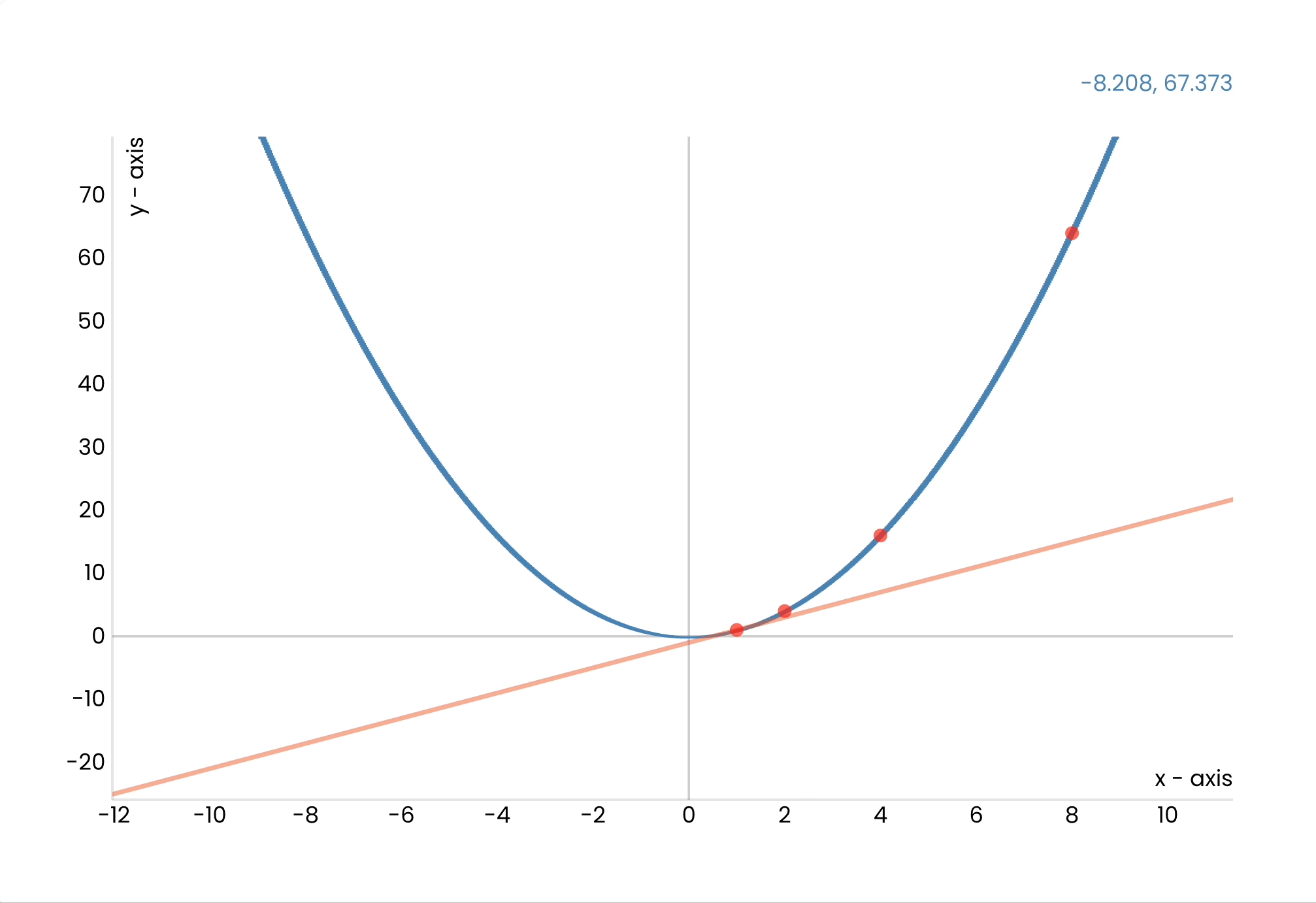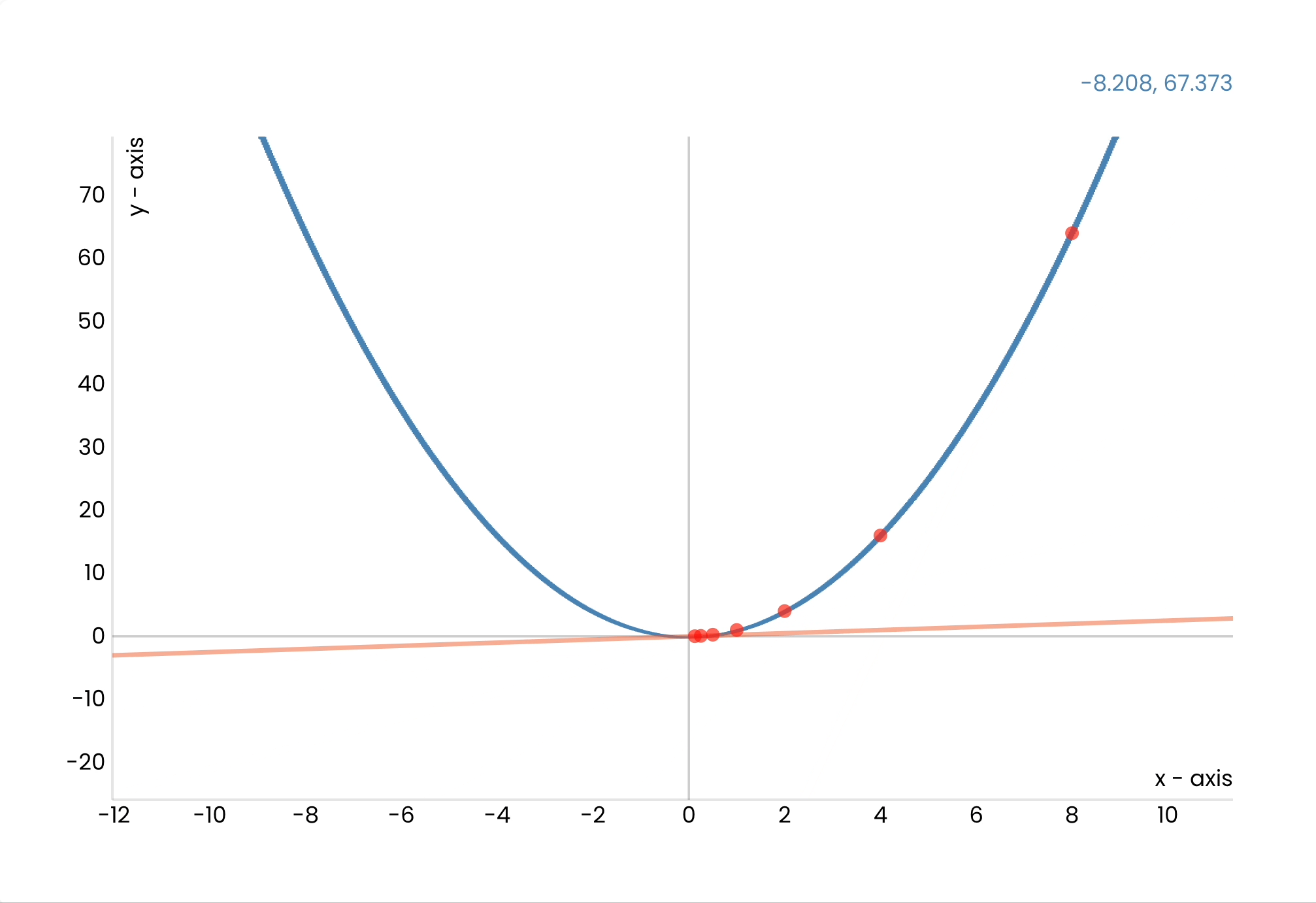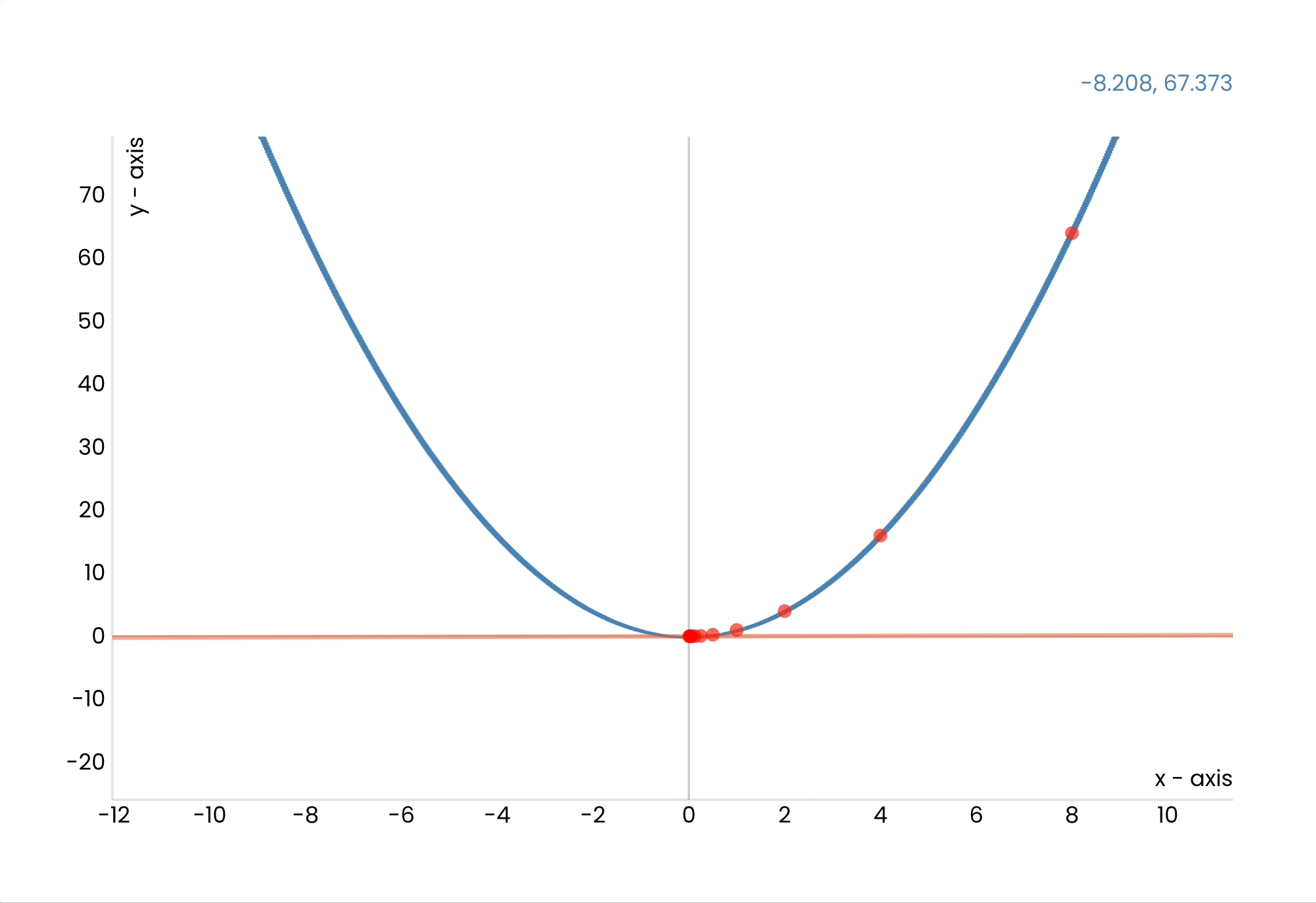
This is called a feed forward neural net - but this simple structure won't be enough to tackle the problem of natural language processing.
Instead LLMs tend to use a structure called a transformer and it has some key concepts that unlock a lot of potential.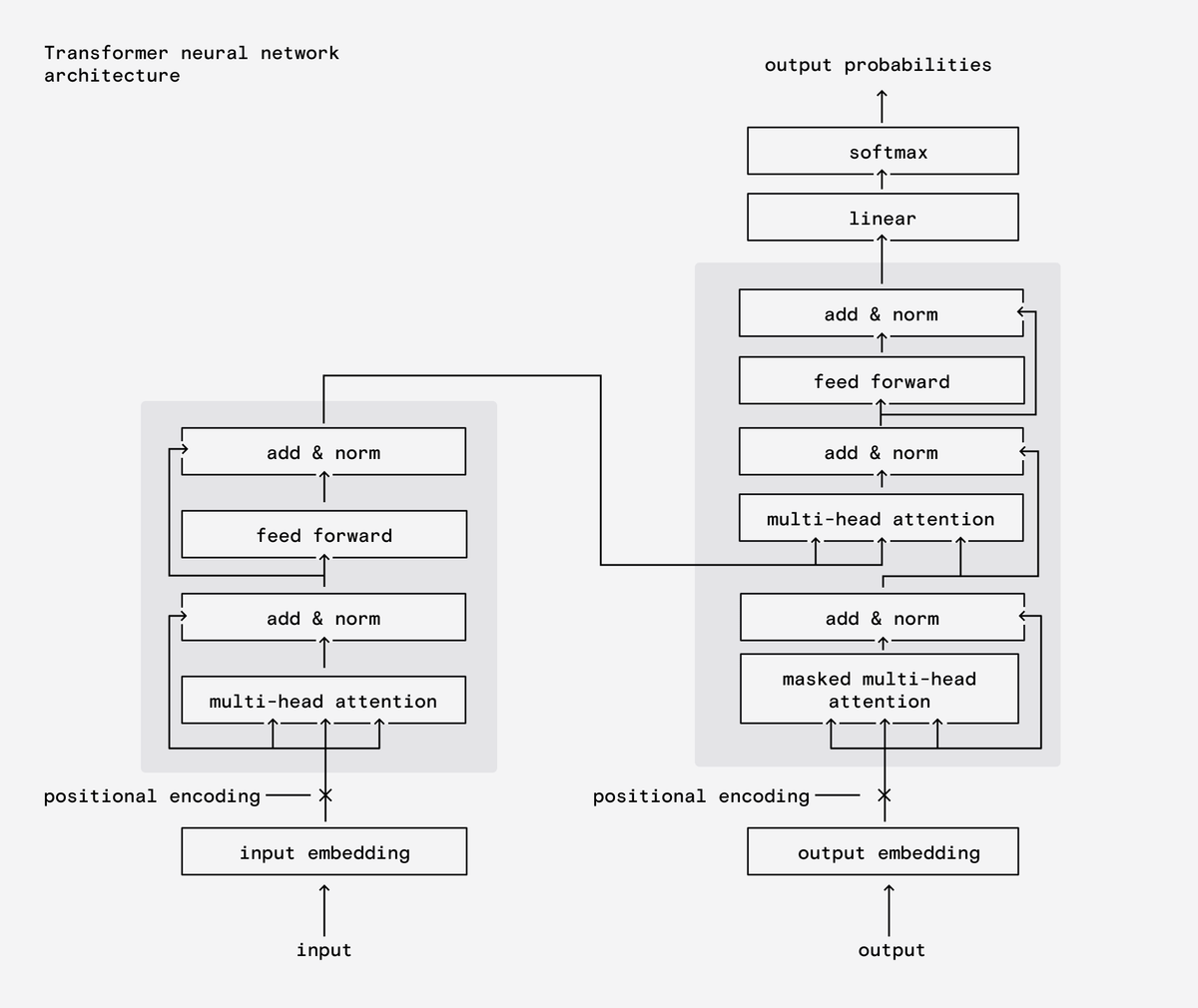
First, lets talk about words.
Instead of each word being an input, we can break words down into tokens which can be words, subwords, characters or symbols.
Notice how they even include the space.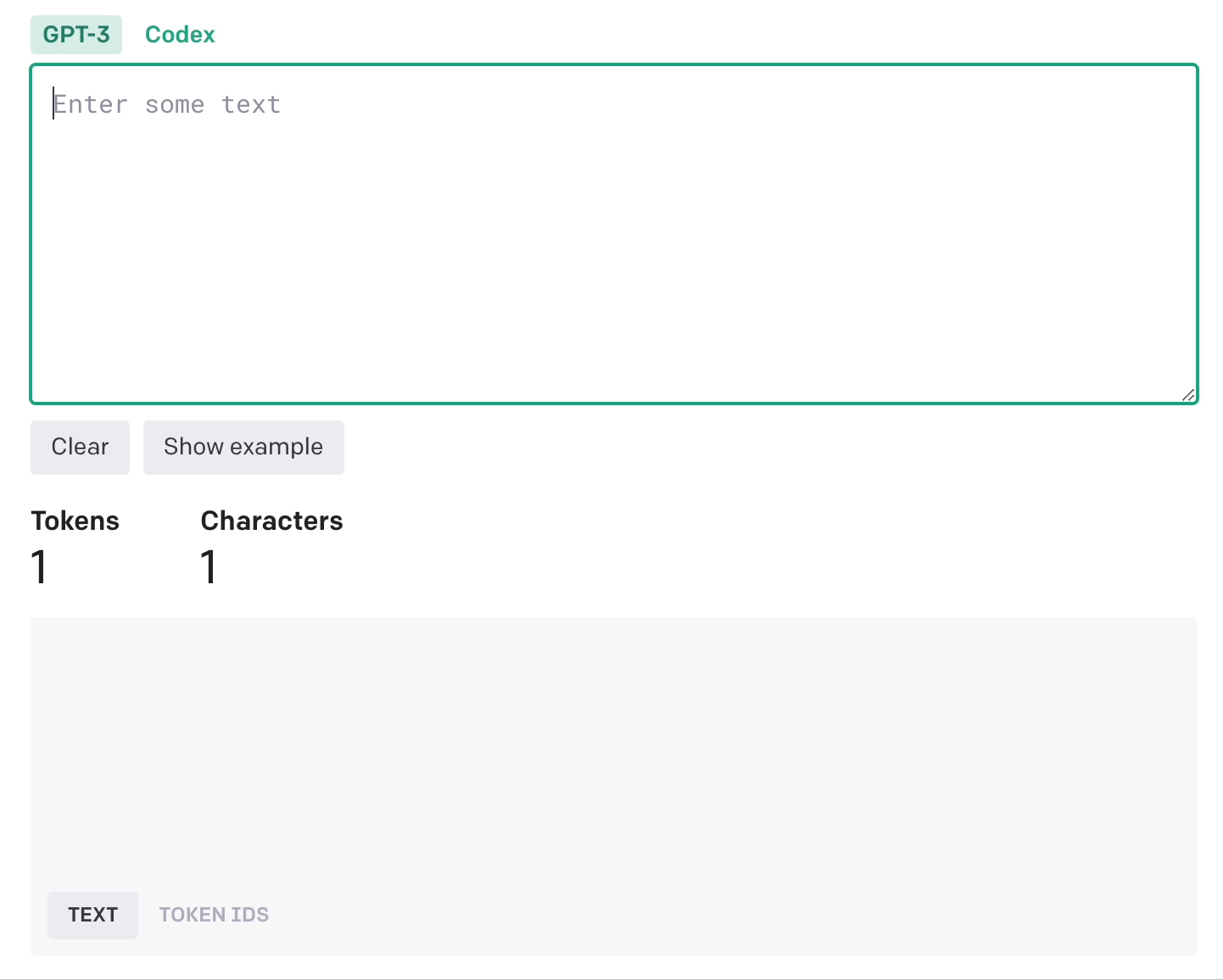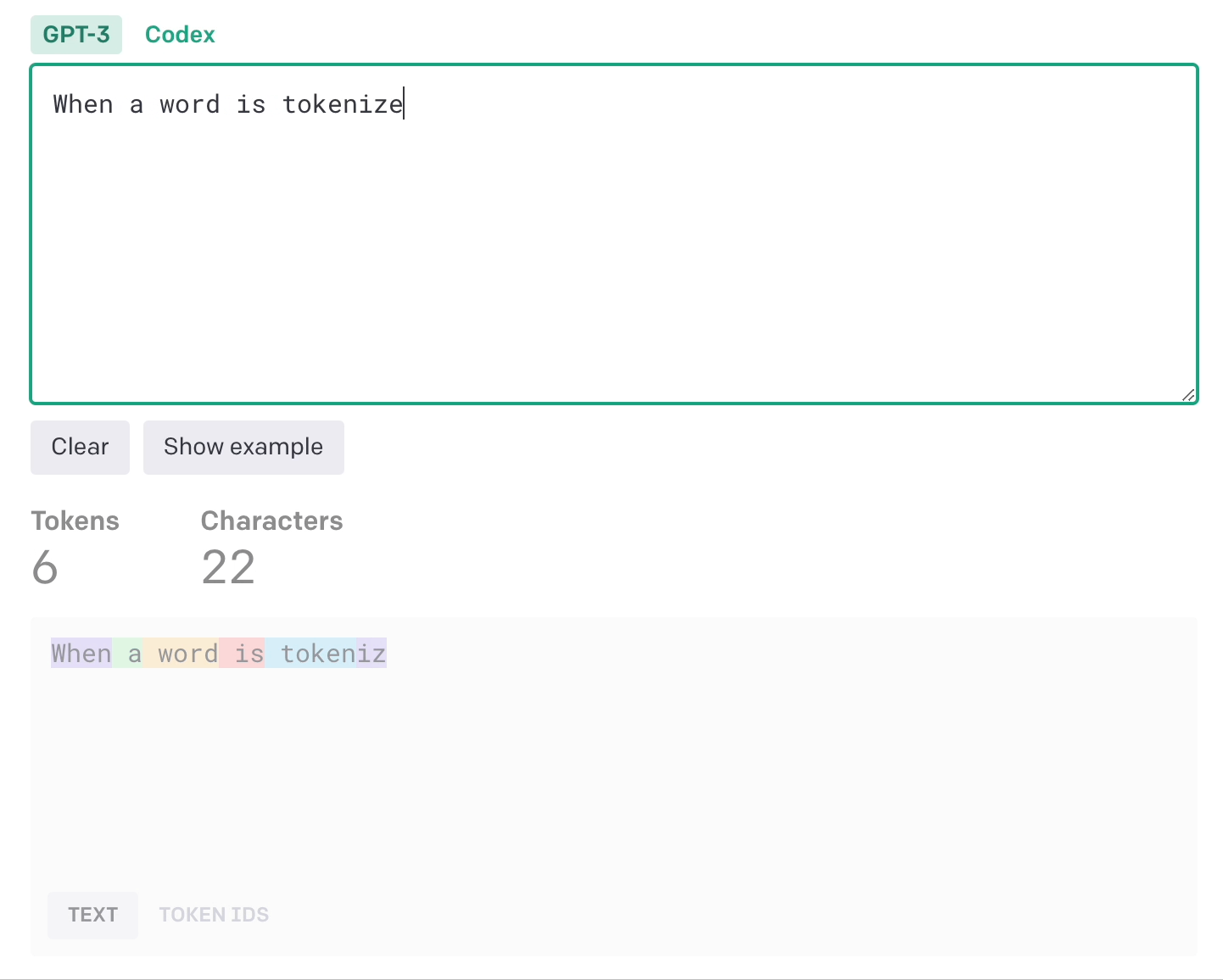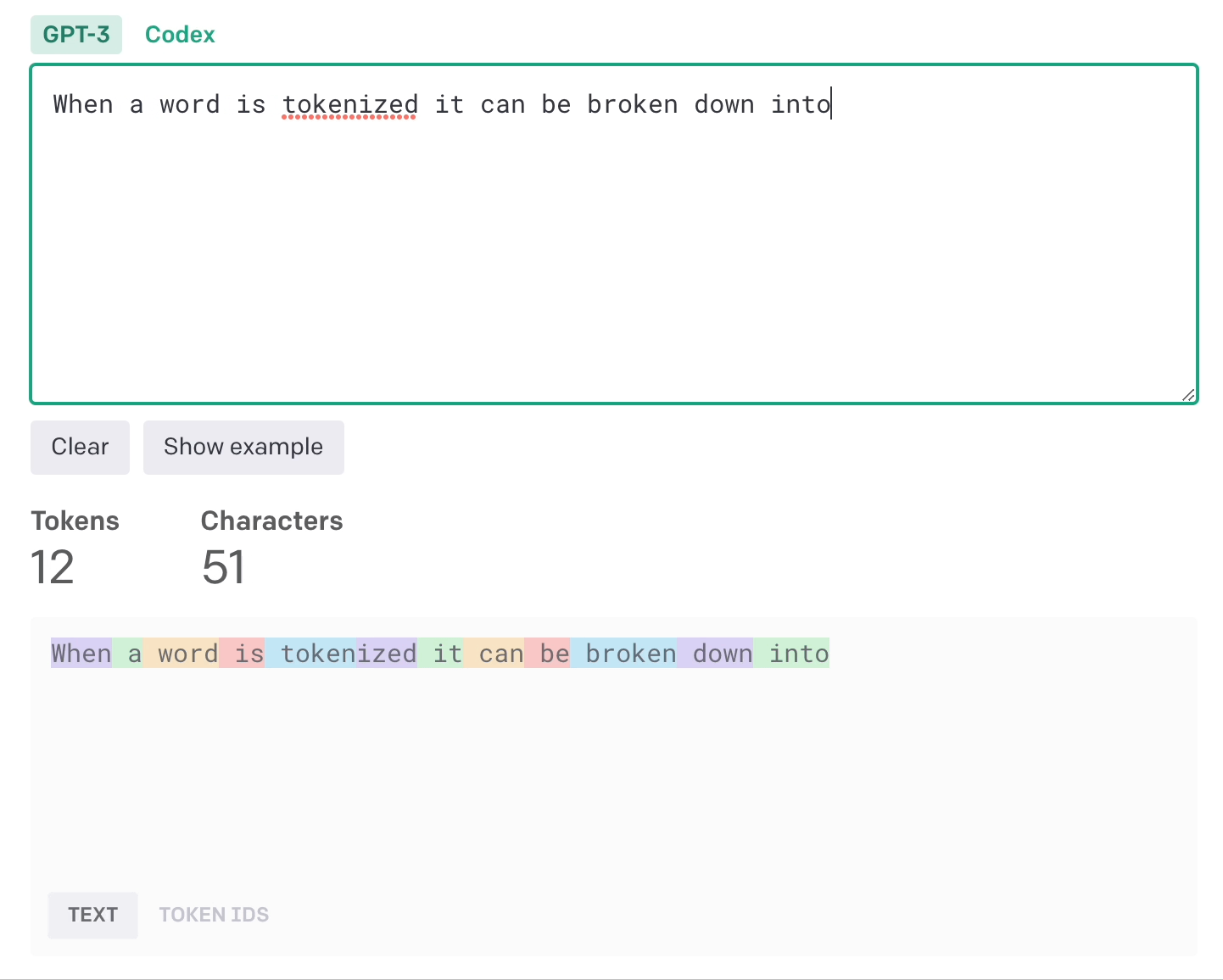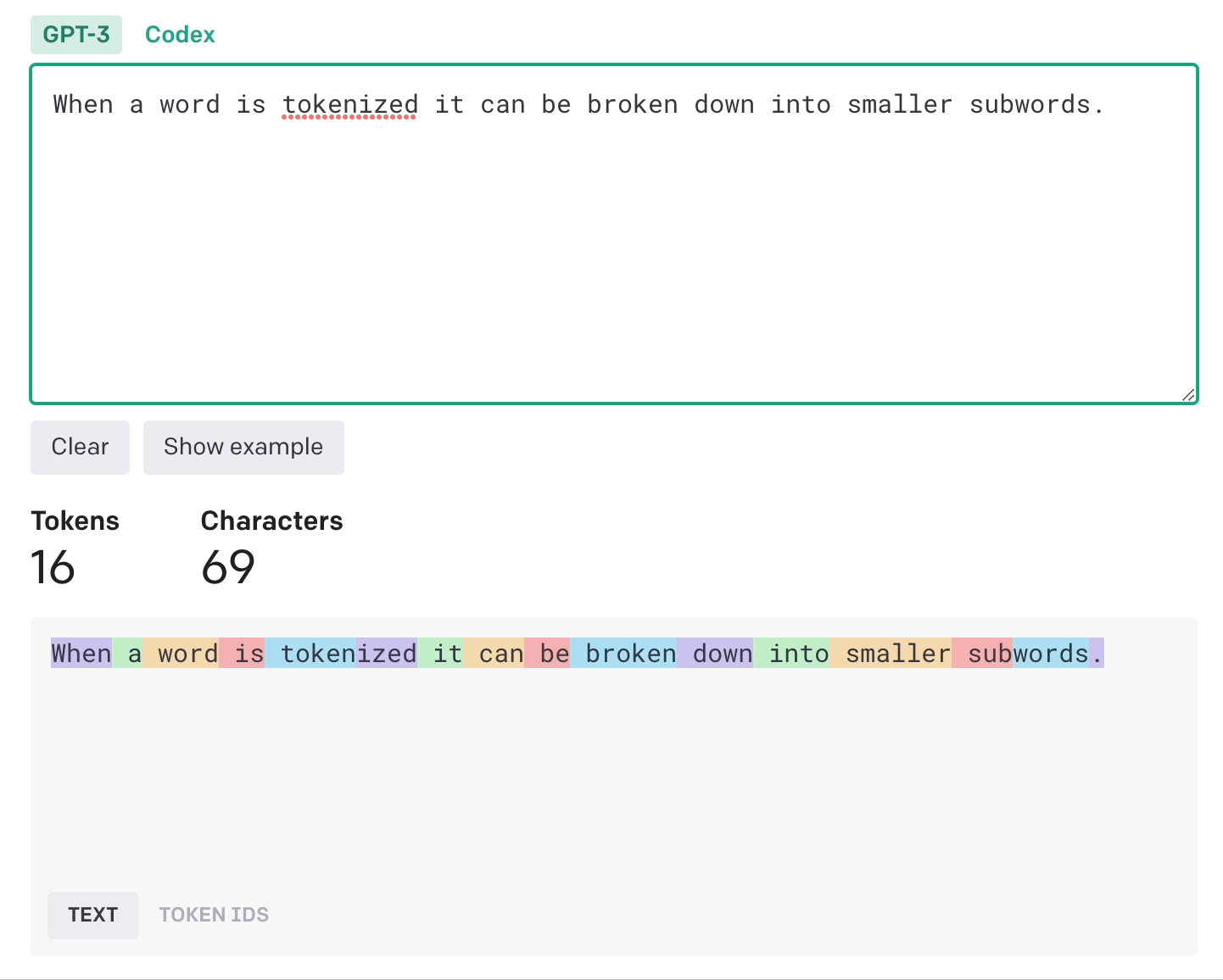
Much like in our model we represent the pixel value as a number between 0 and 1, these tokens also need to be represented as a number.
We could just give each token a unique number and call it a day but there's another way we can represent them that adds more context.
We can store each token in a multi-dimensional vector that indicates it's relationship to other tokens.
For simplicity, imagine a 2D plane on which we plot the location of words. We want words with similar meanings to be grouped closer together.
This is called an embedding.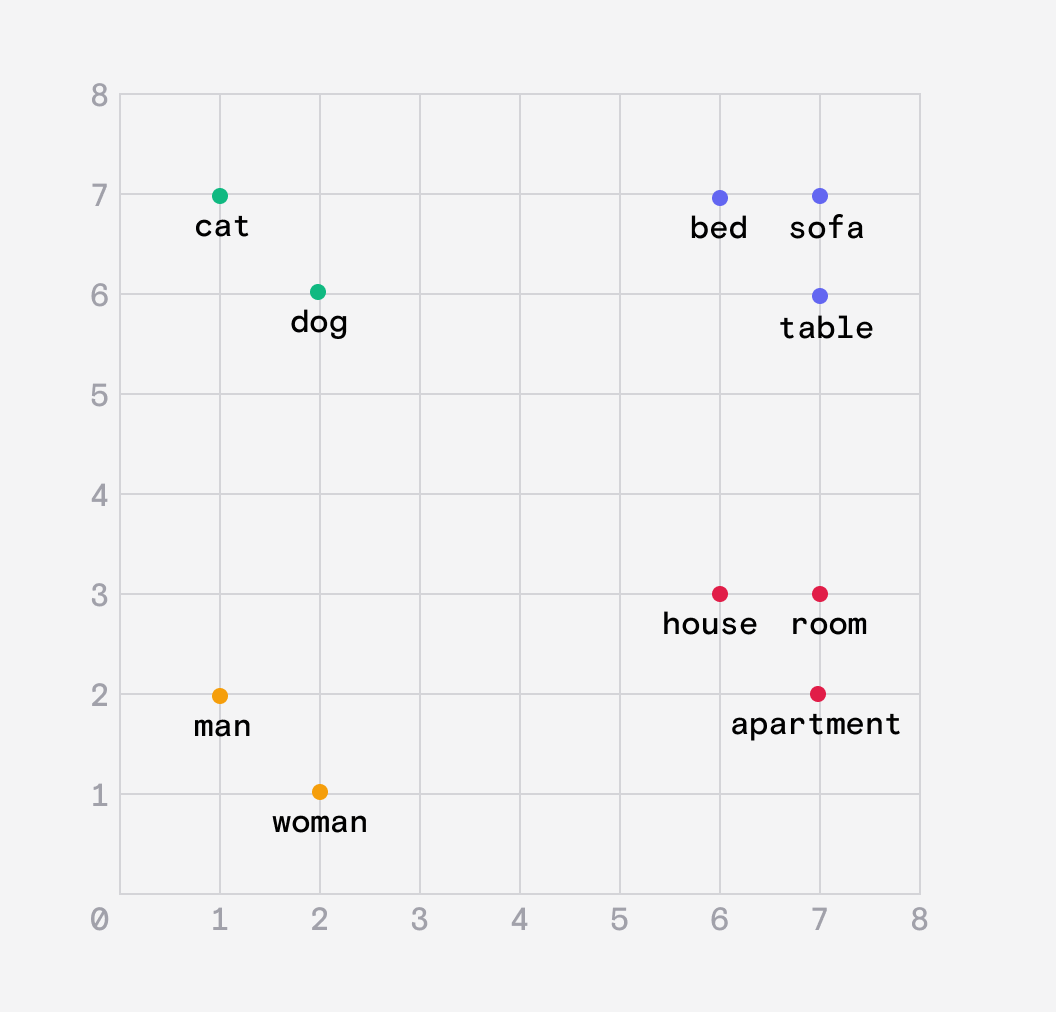
Embeddings help create relationships between similar words but they also capture analogies.
For example the distance between the words dog and puppy should be the same as the distance between cat and kitten.
We can also create embeddings for whole sentences.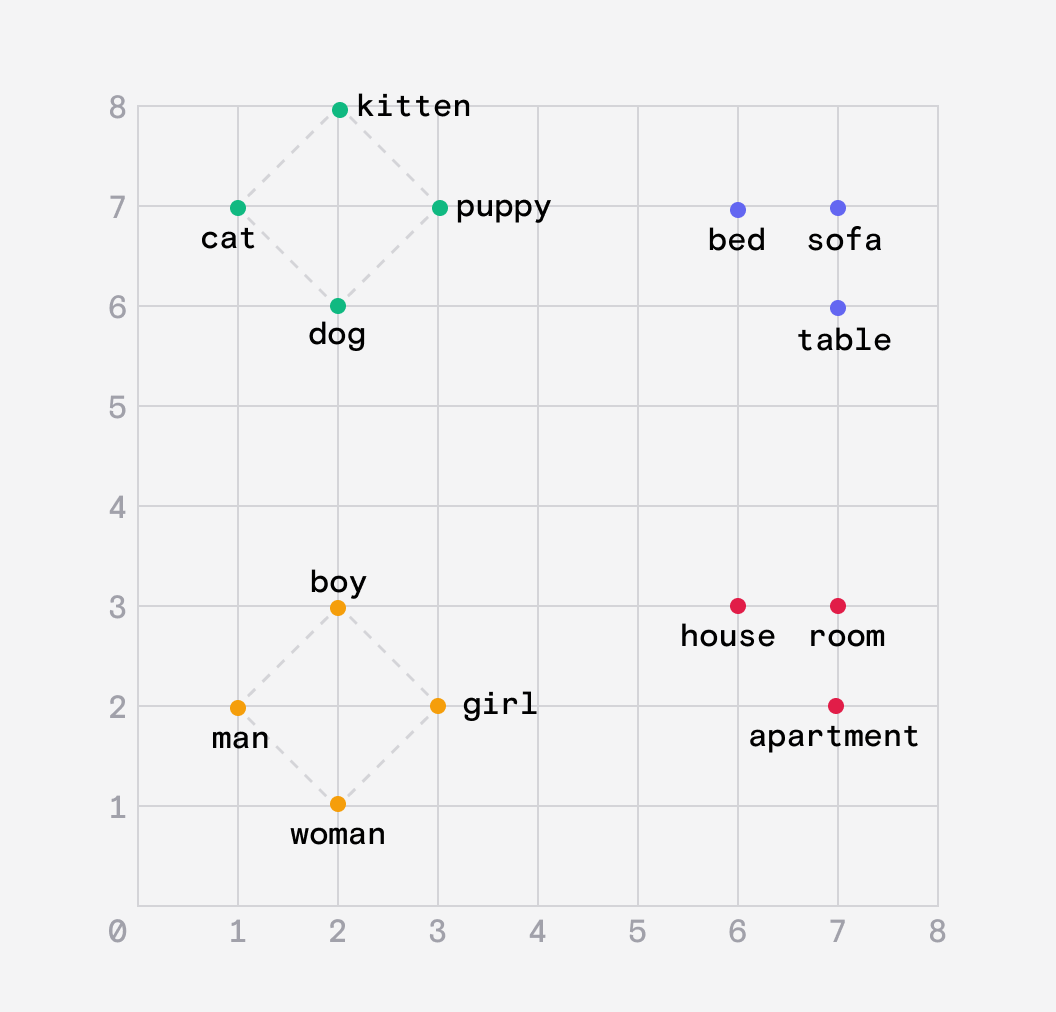
The first part of the transformer is to encode our input words into these embeddings.
Those embeddings are then fed to the next process, called attention which adds even more context to embeddings.
Attention is massively important in natural language processing.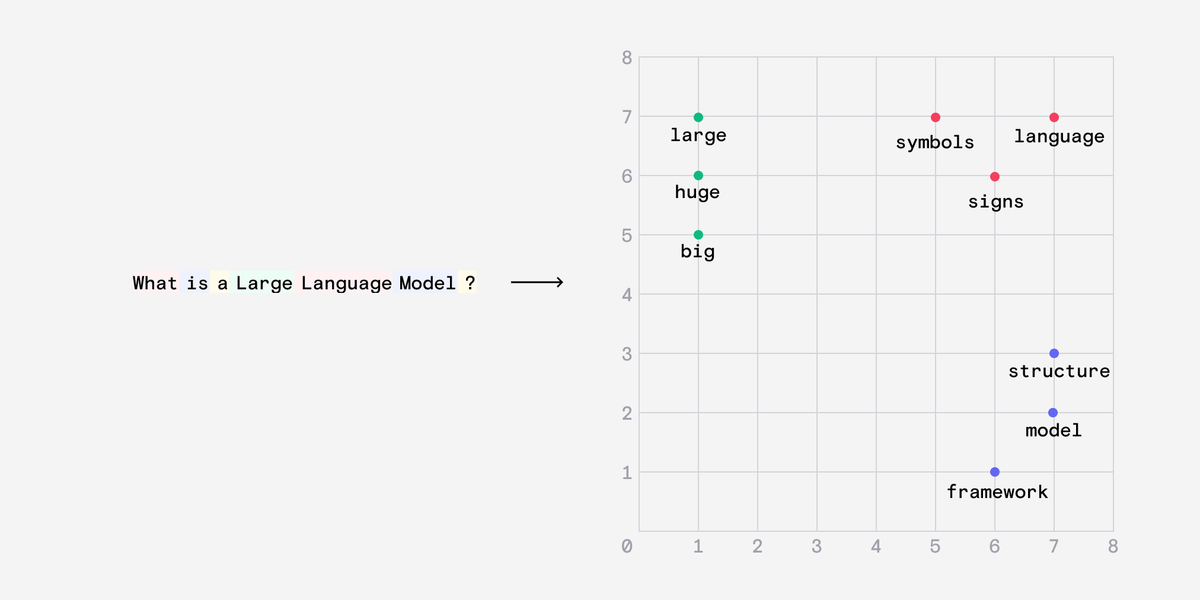
Embeddings struggle to capture words with multiple meanings.
Consider the two meanings of 'bank'. Humans derive the correct meaning based on the context of the sentence.
'Money' and 'River' are contextually important to the word bank in each of these sentences.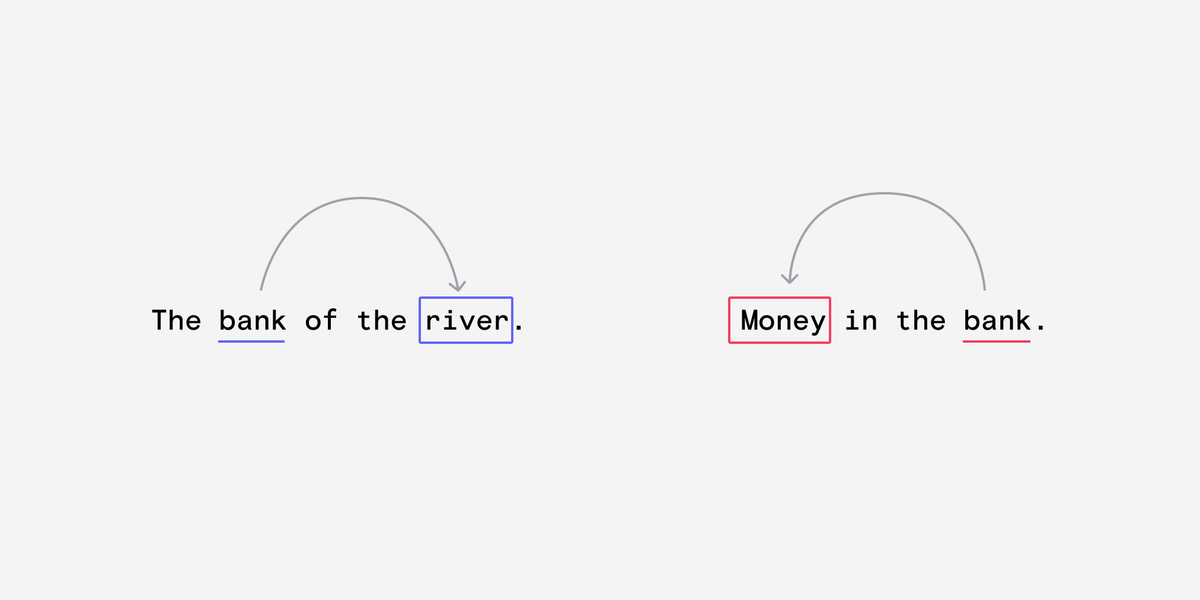
The process of attention looks back through the sentence for words that provide context to the word bank.
It then re-weights the embedding so that the word bank is semantically closer to the word 'river' or 'money'.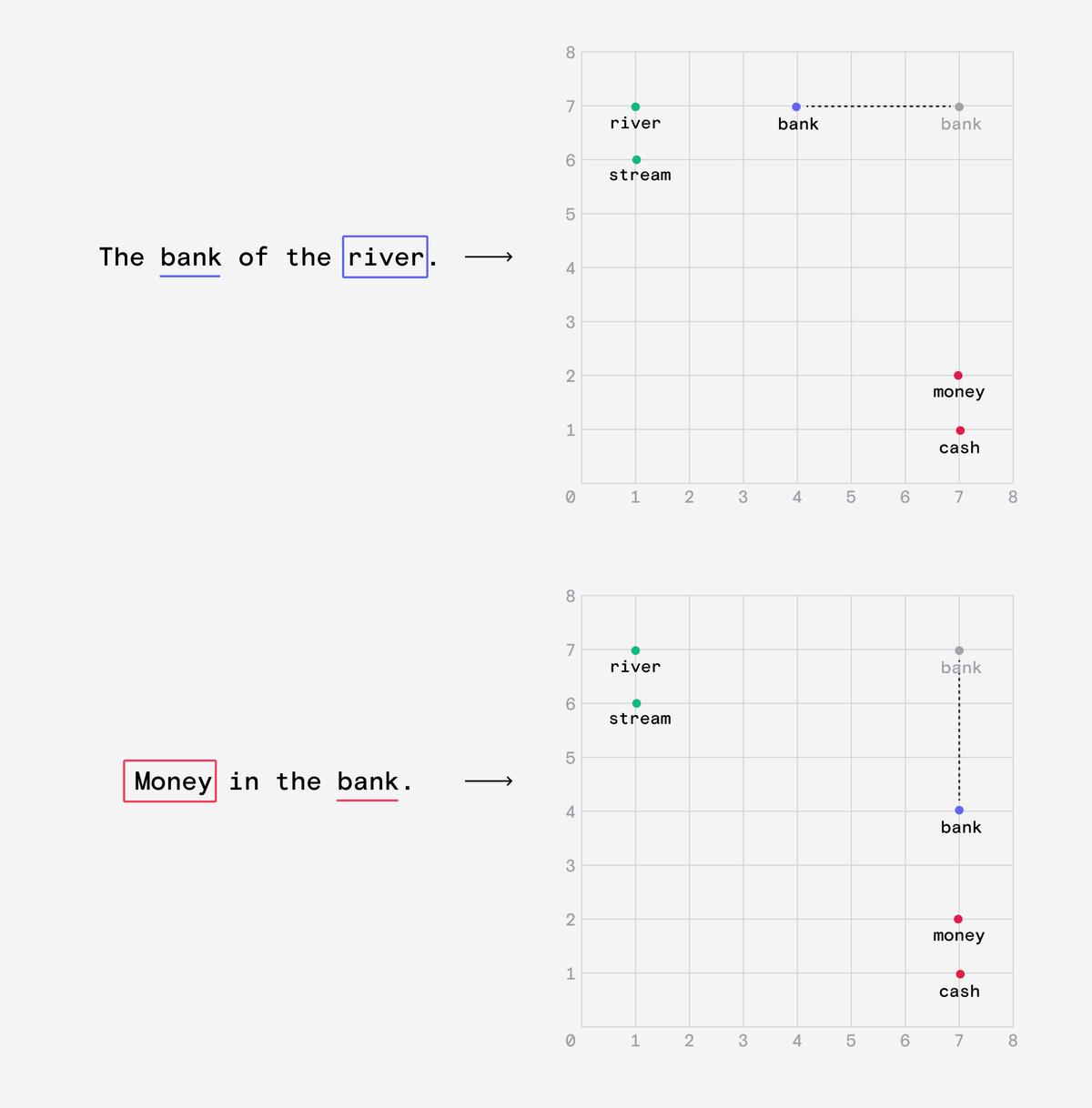
This attention process happens many times over to capture the context of the sentence in multiple dimensions.
After all this, the contextualised embeddings are eventually passed into a neural net, like our simple one from earlier, that produces probabilities.
That is a massively simplified version of how an LLM like ChatGPT actually works. There is so much I've left out or skimmed over for the sake of brevity (this is the 20th tweet).
If I left something important out or got some detail wrong, let me know.
I've been researching this thread on/off for ~6 months. Here are some of the best resources:
Obviously this absolute unit of a piece by Stephen Wolfram which goes into much more detail than I have here:
writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
For something a bit more approachable, this @3blue1brown video series about how neural nets learn.
There are some lovely graphics here, even if you don't follow all the maths.
youtu.be/aircAruvnKk?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
And @CohereAI's blog has some excellent pieces and videos explaining embeddings, attention and transformers.
txt.cohere.ai/what-is-attention-in-language-models/
txt.cohere.ai/sentence-word-embeddings/
You may now let go of your butts.

Dan Hollick
@DanHollick
design engineer @tailwindcss. writing a book about software at makingsoftware.com prev: @raycastapp