¿Quieres saber si tu web ha sido usada para entrenar modelos de IA como T5 de Google, o LLaMA de Facebook? 💡
Tenemos una herramienta para consultarlo. 🔧 E incluso podrás saber qué porcentaje de tokens del total se han tomado de cada web incluida en la base de datos.
1/15 🧵
C4 es un corpus con textos extraídos de millones de webs en abril de 2019.
Este rastreo es obra de Common Crawl, organización sin ánimo de lucro que cada dos meses crea una "copia" de una parte representativa de internet, pública y disponible para el que la quiera.
2/15
OpenAI también usó Common Crawl para entrenar a GPT-3 (confirmado, aunque no sabemos exactamente qué parte) y presumiblemente también lo ha usado para GPT-4, aunque en este caso no tenemos confirmación.
3/15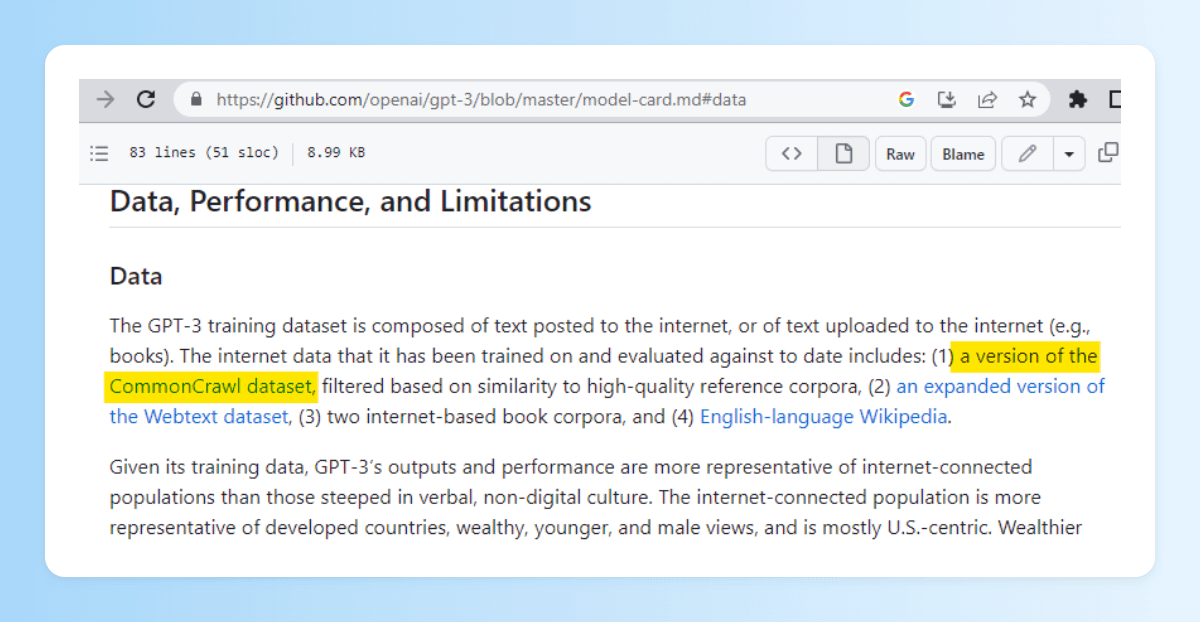
C4 será probablemente muy parecido en su composición al dataset de Common Crawl usado para GPT-3.
Por supuesto, todos los modelos usan fuentes adicionales en su entrenamiento, pero nos sirve para tener una idea del contenido procedente de internet que han usado.
4/15
El Washington Post ha publicado un artículo muy completo analizando la composición de este corpus, y lo mejor es que incluye un buscador donde puedes comprobar si tu sitio, o el que tú quieras, está presente en C4 y en qué proporción.
Pruébalo aquí: washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
4/15
Las webs más usadas son, en este orden, el directorio de patentes de Google, Wikipedia, Scribd y el New York Times.
En cuanto a temáticas, las princpiales son negocios/industrial con un 16% del contenido, tecnología un 15% y noticias un 13%, pero casi siempre en inglés.
6/15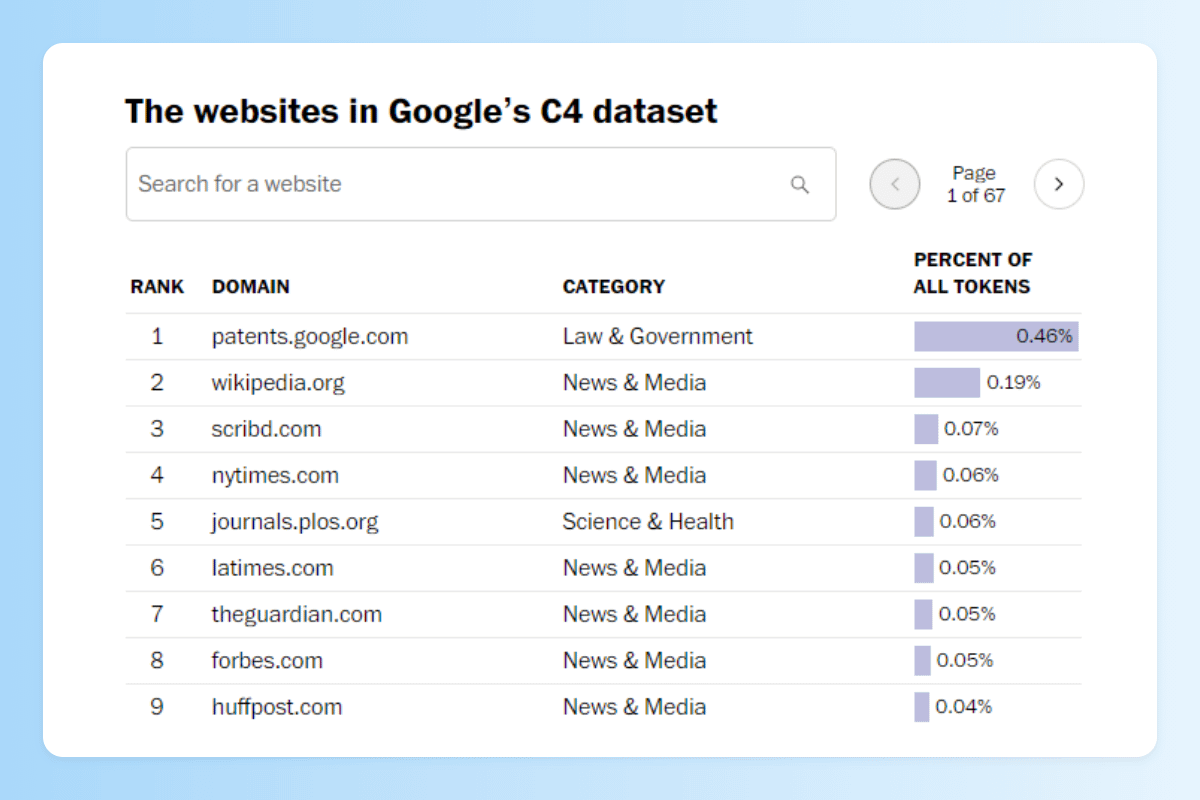
C4 se centra en textos en inglés "natural y de calidad", por lo que las webs en español y en otros idiomas están muy poco representadas.
La más alta que he encontrado en el ranking es El País, con un 0,0004% de los tokens (y un puesto 26.649 en el ranking).
7/15
En cuanto a webs del sector marketing / SEO me ha llamado la atención ver a @semrush muy bien clasificada. 👍
8/15
En fin, ¿por qué es importante esto (aun cuando no se trata del dataset de entrenamiento de ChatGPT, que está en boca de todos?
Porque aporta transparencia sobre la procedencia concreta de los datos, que es algo que hasta ahora se está echando un poco de menos.
9/15
Como se supo hace unos días, la UE prepara algunas medidas "duras" de cara a ChatGPT y simialres, y entre ellas podría estar la obligación de revelar si se han usado datos con copyright, para en su caso poder establecer una compensación a los propietarios de los datos.
10/15
Puede que de aquí en adelante veamos más iniciativas de este tipo, e incluso que sea requisito legal para poder comercializar o hacer público un chatbot.
Y esto nos lleva al problema de la compensación, que creo que va a ser importante en los próximos meses:
11/15
Es decir, ¿qué ofrecen las empresas como OpenAI a cambio de usar los datos de una web para entrenar sus modelos?
Por un lado está el precedente de iStock que ha demandado a Stable Diffusion por usar imágenes de su colección (con marca de agua y todo) en su entrenamiento
12/15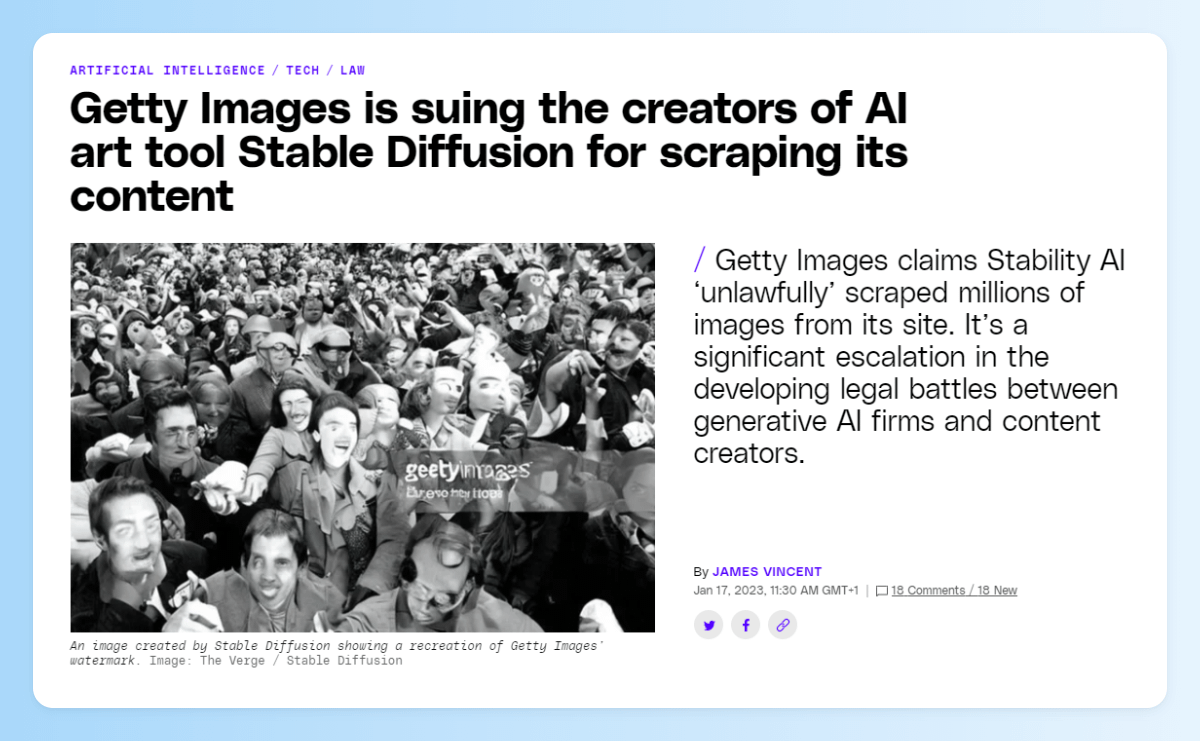
Y hace nada, hemos sabido que Reddit hará su API de pago, para forzar a pagar a cualquiera que quiera entrenar un modelo con sus datos:
nytimes.com/2023/04/18/technology/reddit-ai-openai-google.html
13/15
¿Será pronto esta la tónica habitual? ¿Afectará esto a Google buscador?
En principio, Google "recompensa" a las webs cuyo contenido indexa enviando trafico, y ese tráfico puede llegar a tener mucho valor. ChatGPT, en cambio, no envía ningún tráfico...
14/15
Y la situación puede hacerse más compleja si crece el uso de Bing Chat, que ya envía "algún" tráfico hacia webs (pero menos que un buscador tradicional), y sobre todo si Google integra chatbot en sus resultados (quizá en mayo).
¿Qué harán los publishers entonces? 🤔
15/15
Gracias por leer hasta aquí.
Si te ha gustado el hilo, agradezco FAV y RT al primer tuit del hilo, y te invito a suscribirte a mi newsletter Mentes Artificiales.
Las principales noticias y recursos de IA, una vez a la semana:
useo.es/mentes-artificiales/

Juan González Villa
@seostratega
Consultor SEO y divulgador sobre IA. Dirijo @AgenciaUSEO, equipazo especializado en SEO internacional y para ecommerce. Soy un loco con dos newsletters. 😅