I recently talked on @EFDevcon about my learnings from the @nomadxyz_ hack, which saw about $190M in tokens drained from the Nomad Bridge.
Probably one of the most painful experiences I have ever had.
A quick thread 🧵 on how I went from Nomad to Very Mad
1/26
Firstly, a small disclaimer:
The views I express today are my own and do not reflect Illusory Systems (the company behind Nomad)
Feel free to watch the presentation here:
youtube.com/watch?v=Ow8YXfv02Jo
2/26
Nomad is NOT a bridge.
Nomad has a bridge.
Nomad is an optimistic protocol for interoperability that supports arbitrary messages between domains.
A bridge is just an application on top of a message-passing channel.
3/26
But how Nomad works?
Messages sent from a domain are added to a Merkle Tree. The tree's root compresses the information about whether a message belongs to the tree.
Nomad simply needs to send the root from one domain to another. The messages can be proven on that domain.
4/26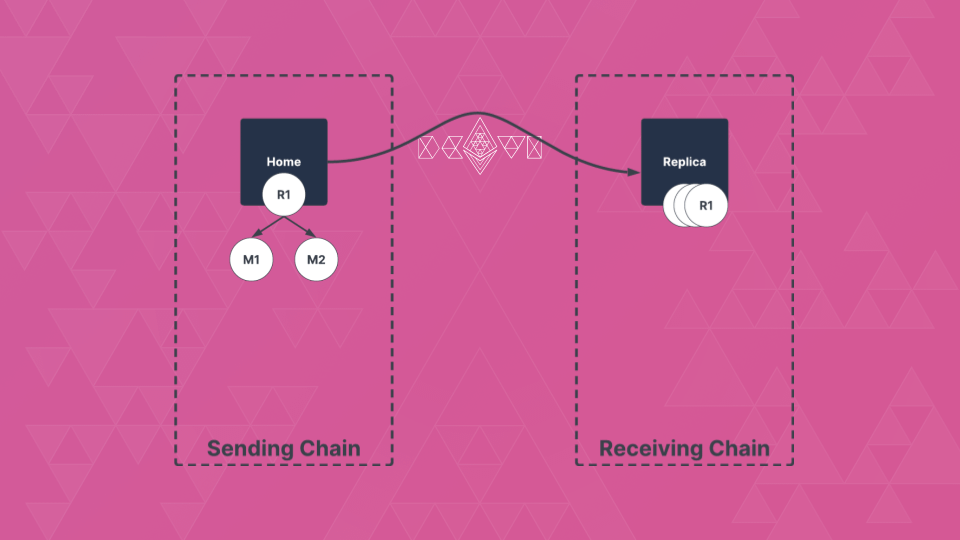
A message is sent from a domain by calling the Home contract. It will add the message to the Merkle Tree, which updates the tree's root.
After the root is relayed to the Replica contract, we wait for the optimistic window and finally can prove and process messages.
5/26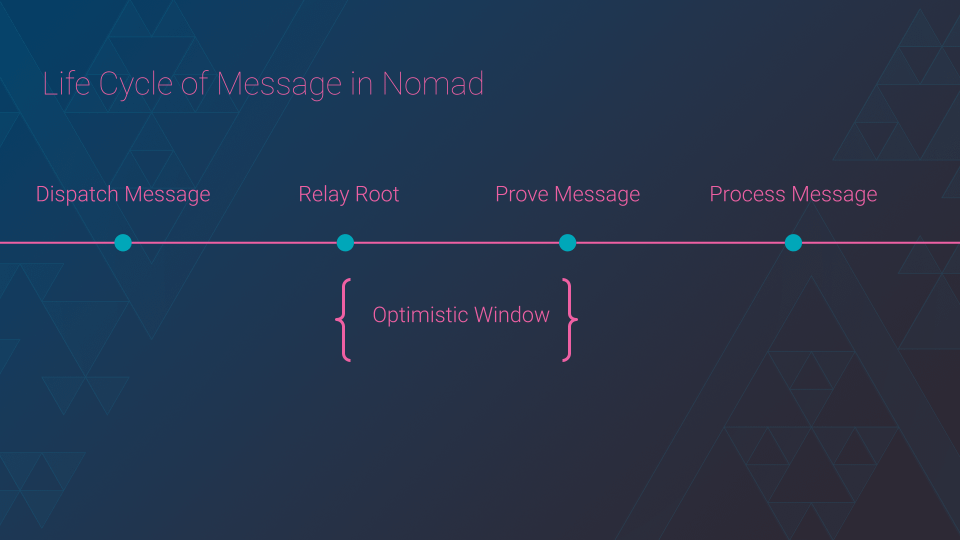
But how does a bridge work?
The user sends native tokens on the sending chain to the bridge. It locks native tokens on the sending chain and mints representation tokens on the receiving chain. These tokens have value only because they can be redeemed for the native ones.
6/26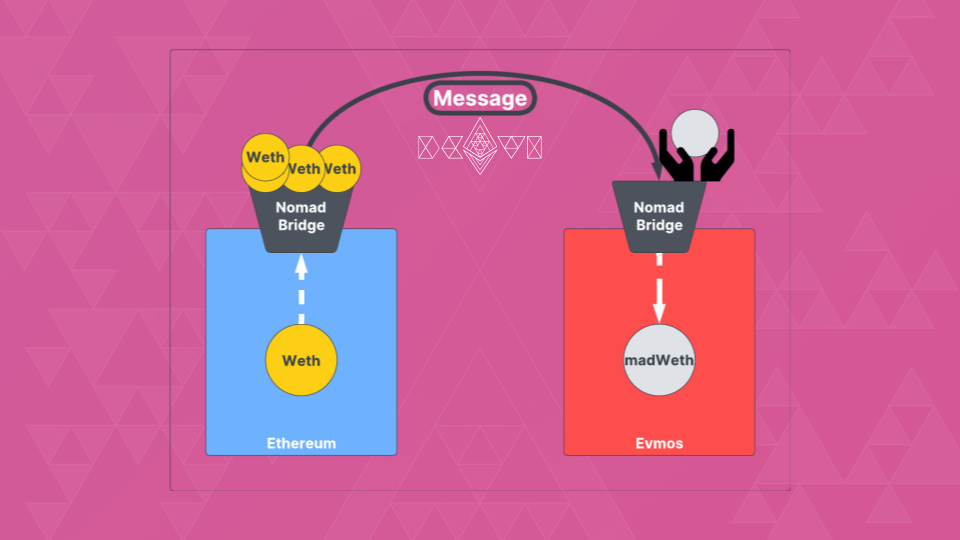
IMHO, this is why bridges are hacked so often.
They are not only complex systems but also own tons of collateral. They are juicy targets that attract a lot of eyes.
Without collateral, users can't redeem back their representations.
7/26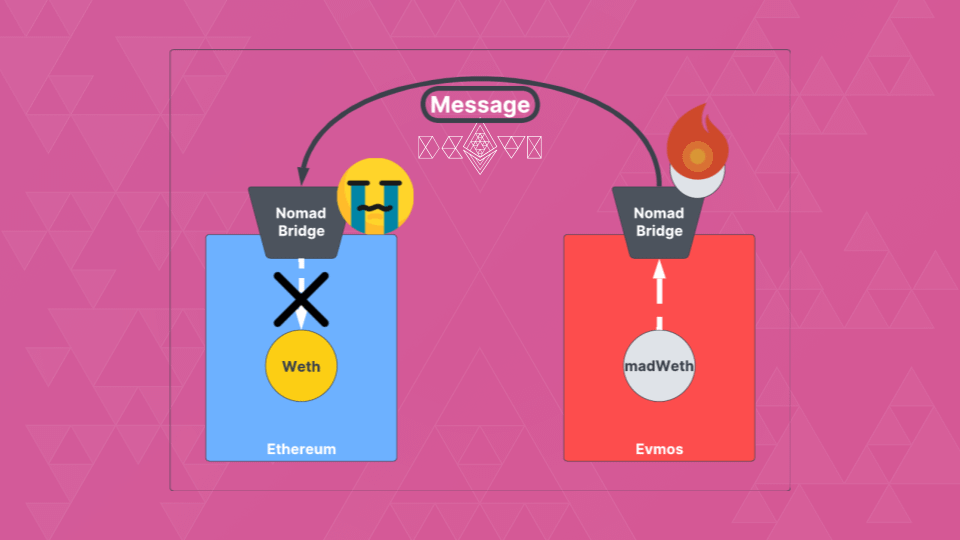
Root Cause Analysis
A bug caused the Replica contract to fail to authenticate messages properly. This issue allowed any message to be forged.
@coinbase did an excellent incident analysis on this
coinbase.com/blog/nomad-bridge-incident-analysis
8/26
Currently, the Nomad Protocol is paused.
Restarting the Protocol is easy.
Restarting an under-collateralized Bridge is hard.
We want people to:
a) Collect funds whenever tokens exist in the bridge
b) Collect funds fairly
Follow @nomadxyz_ for updates and design details.
9/26
✅ My Suggestions for protocol devs:
Bismarck said that only a fool learns from his own mistakes. A wise man learns from the mistakes of others, so I would advise you to take note.
10/26
I grouped my suggestions into four categories:
• Test
• Observe
• Engage
• Communicate
Think of them as multiple defenses of a castle. You layer them properly and hope the attackers won't breach the citadel.
11/26
🛠 Test 🛠
➡️ Testing
• unit tests
• property-based tests
• integration tests
• forking tests
• invariant tests
➡️ Honorable mention
• static analysis
• storage layout inspection
🔥 Use foundry 👇
getfoundry.sh/
12/26
In my mind, priority should be in
- Unit Tests
- Property-based tests
- Forking Tests
- Audits
Moreover, I think that protocols should seriously consider."
- fork tests (bugs often require on-chain state to get surfaced)
- invariant tests (provably secure protocol)
13/26
👉 Quick plug
I created a simple script that you can add to your CI and verify that the storage layout of your contracts does not change without you noticing.
**A LOT** of the hacks that happened to upgradeable contracts were due to this.
github.com/odyslam/bash-utils
14/26
👁 Observe 👁
If you receive "u up" and aren't already up, it's already too late
15/26
Alerting in web3 is nascent, but it's a solved problem in Web2.
1. Start with Business Objectives
2. Define Actionable Alerts
3. Define Playbook for every Alert
4. Beware of Alert Fatigue 😴 (ignore alerts)
Read the Google SRE handbook: sre.google/sre-book/monitoring-distributed-systems/
16/26
IMHO, we can group on-chain alerting into two large groups:
1. Hereustic-based alerts. Define rules, but require human intervention to interpret
2. Invariant-based alerts. If invariants break, then alert. Mitigation can be automated due to its binary nature (true/false)
17/26
An interesting note about "Invariant-based" alerts:
Interestingly, @rikardhjort from @rv_inc mentioned a similar use of continuous invariant testing as part of an alerting system in his talk "Formal method for the working DeFi dev"
Expect more 🤙
archive.devcon.org/archive/watch/6/formal-methods-for-the-working-defi-dev/
18/26
⚔️ Engage ⚔️
It's now the time to manage an incident.
Prepare for the incident. Have explicit ownership of all the deliverables (which should also be precise).
Unless you have simulated it before, you won't react in time under stress and extreme time constraints.
19/26
Read The Anatomy of a Good Emergency Procedure by our good friends at @TenderlyApp and @iearnfinance and adapt it to your organization.
Then run gamedays for the entire org.
blog.tenderly.co/what-good-war-room-emergency-procedure-yearn-finance-case/
20/26
🗣 Communicate 🗣
Now that everything is said and done. It's time to face the music.
Although we always have the user in mind, we shouldn't talk to anyone. Not a tweet, not a GitHub commit, nothing.
First, we talk with our legal team.
Then, we talk with users.
21/26
Let's see an example timeline for the first hours/days after the incident:
1. Inform legal
2. Inform users
3. Inform partners
4. Get a chain analytics firm
5. Setup a recovery address
6. Align with legal on a bounty
7. Inform users
🔁 Rinse and repeat steps 1,2,3,4
22/26
A note on chain analytics firms:
They provide valuable information to Legal Enforcement Agencies (which are contacted via your legal team). They also help with asset recovery, as people have a sudden change of heart as LEA zeroes in their real identity. 🤷♂️
23/26
Expect Asset Recovery to be a parallel workstream to everything you do. It will continue to consume human resources and capital throughout the following months of operations as you:
• mitigate the hack
• restart the protocol
• figure out the way forward
24/26
I am sure multiple protocols are thinking about the same issues, so I am always looking for cool stuff to collab on and make the space a tiny bit more secure.
I hope I have given you a map you can use as you develop your protocol. Security shouldn't be an afterthought.
25/26
I feel truly blessed to work alongside @annascarroll , @_prestwich , and the rest of the Nomad crew.
You can be sure that the Nomad team is working overtime to push the protocol forward and restart the bridge. I couldn't have asked for better teammates.
26/26
You can read the unrolled version of this thread here: typefully.com/odysseas_eth/XQskWEh

Odysseus | phylax.systems
@odysseas_eth
ceo @phylaxsystems / adv @arete_xyz The society that separates its scholars from its warriors will have its thinking done by cowards and its fighting by fools